AI neutrality circulates widely as an ideal, but is such a state actually possible? This article explains the three types of bias in LLMs, what prompt-based mitigation really achieves, and how to support stable reasoning inside QA workflows.

The discussion about bias in large language models often appears abstract, even philosophical. But inside engineering teams, bias shows up in very concrete ways. It affects prioritization, validation, documentation, and any task where the model’s reasoning influences quality.
A slight change in wording can shift the depth of an analysis. A model can favor one style of documentation simply because it has seen more of it. Or it can reorganize its reasoning from one run to the next, even when the input barely changes.
At Abstracta, we work at the intersection of quality engineering and language understanding, where domain knowledge, tools, and reasoning patterns come together in real workflows.
This article clarifies the different forms of bias that affect real operations, how prompt engineering interacts with them, and how teams can guide a model toward behavior that stays consistent to support QA and delivery.
If you’re evaluating model behavior inside your QA or delivery workflows and need support setting guardrails or decision structures, reach out to us.
The Three Types of Bias
Before asking whether bias mitigation in prompt engineering can lead to “neutral” results, we need to clarify what we mean by bias. The term covers several different phenomena, and discussions in research, industry, and engineering often refer to different things.
In practice, most conversations revolve around three main types of bias in large language models.
1. Social or Cultural Bias
This includes unfair associations or stereotypes the model learned from human-generated text. It’s the form of bias most frequently covered in Responsible AI work, public discussions, and industry guidelines. When people ask whether prompt engineering can “neutralize” bias, they often mean this category.
2. Data or Model Bias
This refers to imbalances, gaps, or overrepresentations in the training data itself. A model may favor certain domains, writing styles, technical dialects, or sources simply because it has seen more of them. Prompt engineering can sometimes redirect this behavior, but it cannot erase the underlying distribution the model learned.
3. Operational Bias
This is less about social meaning and more about variation in how the model reasons. It appears when the model changes depth, structure, or analytical focus in response to subtle wording differences. For teams using LLMs in workflows, this form of bias affects consistency, reviewability, and the ability to compare outputs reliably across runs.
All three forms of bias matter, and prompt-based mitigation interacts with each in different ways. It can guide the model away from harmful associations, steer its attention when the training data is uneven, and reduce unwanted variation in reasoning. But none of these interventions produces complete neutrality.
What they offer instead is a narrower, more predictable range of behavior, something closer to stability than to neutrality.
How Prompt-Based Mitigation Works in Real Teams
When teams refine prompts to reduce biased outputs, the intention is usually to create responses that follow a steadier line of reasoning. This work touches different forms of bias at once: social or cultural associations, imbalances inherited from the training data, and variations in how the model reasons through similar tasks.
The adjustments aim to keep the model focused, reduce noise, and avoid shifts that appear when small changes in wording or context are introduced. This adds more uniformity to the output, which helps during reviews and decisions that depend on consistent signals.
The model follows patterns learned during training. Those patterns shape how it interprets information and how it forms conclusions. Prompt refinement doesn’t neutralize these patterns, but it narrows the range of variation enough for teams to review and understand the model’s decisions.
Why Neutrality Is Not a Realistic Target in Engineering Contexts
In professional conversations, AI neutrality is often described as the idea that a model could produce answers free from preferences, patterns, or influences learned during training.
These influences can include social tendencies, imbalances in the data, or variations in how the model structures its reasoning. It is presented as a state where the model’s reasoning doesn’t shift when the wording, tone, or framing of a question changes.
In practice, models rely on learned associations that remain active across all outputs. Neutrality, understood as the absence of these internal influences, doesn’t appear in the environments where teams use models to support engineering decisions.
How Engineering Teams Experience the Issue
Teams exposing models to real delivery conditions see how wording, prompt structure, and operational context shape every response. In these settings, the goal is not neutrality. The goal is a form of stability that allows engineers to review the answer, understand how the model arrived at it, and decide whether it fits the conditions of the workflow.
Here, the focus shifts toward clarity and traceability. Teams need outputs that follow a direction they can interpret and evaluate when the model’s reasoning influences prioritization, validation, or decision-making.
Neutrality across all forms of bias is not achievable, but the good news is that consistency is within reach.
Why We Mention “AI Neutrality” at All
The term appears frequently across LinkedIn threads, Responsible AI panels, and research papers from major institutions. Many people encounter it there before they see how models behave under the constraints of engineering work.
Bringing it into the discussion helps set expectations and redirect the conversation toward what delivery workflows actually require: consistent reasoning, stable outputs, and guardrails that help teams understand how conclusions emerge. This reframing makes it clear that the goal is not neutrality but behavior that teams can evaluate.
What Teams Actually Need Instead of Neutrality
Engineering teams rarely search for an abstract ideal. They search for behavior they can interpret, monitor, and incorporate into decisions that shape quality, delivery timing, and operational risk.
Bias mitigation is useful when it helps teams see how conclusions form under real conditions, regardless of whether the influence comes from social tendencies, data imbalances, or variations in reasoning. The goal is to make the reasoning reviewable, not to eliminate the influences that every model carries from training.
Below, we share three elements that guide this work across real environments:
- Consistency Across Similar Conditions
Teams benefit when the model produces reasoning that follows a consistent internal pattern. This helps reviewers compare outputs across runs, detect subtle variations, and understand whether a pattern reflects a real change in the system or a fluctuation in the model’s behavior, regardless of the type of influence behind the variation.
- Traceable Reasoning
Reviewers need to see how the model connected inputs, signals, and domain rules to reach a conclusion. Clear intermediate steps make it possible to validate evidence, document decisions, and understand why two similar inputs produce similar (or different) results.
- Stability Under Guardrails
In delivery environments, the model interacts with tools, datasets, and signals that shift under operational pressure. Stability allows teams to set thresholds, review boundaries, and evaluate the model’s behavior with confidence as conditions evolve, even when those shifts expose different forms of bias.
These three elements form the foundation for integrating model behavior into quality-driven workflows. They give teams practical ways to evaluate responses, strengthen decision-making, and understand how conclusions align with the state of the system.
How Bias Mitigation Behaves Inside Engineering Workflows
Bias mitigation through prompt refinement shapes how a model organizes its reasoning. In QA workflows, this shows up as explanations that follow a more predictable structure, transitions that are easier to read, and outputs that stay connected to the information available in each run.
QA teams use these reasoning adjustments to reduce unexpected variation when the model processes logs, traces, or partial data from changing environments.
What Actually Happens Inside QA Workflows
Throughout a testing cycle, models work with signals influenced by shifting configurations, incomplete inputs, and routine changes in system behavior. Prompt refinement helps the model keep a recognizable reasoning pattern across these conditions. Here we share some common use cases of AI Agents where teams need to succeed in prompt refinement:
- Analyzing long and complex documentation to generate user stories with their corresponding test cases
- Suggesting test cases with consistent depth across similar prompts
- Producing code snippets or validations that stay aligned with the task
- Generating structured QA reports and creating the Jira ticket with the appropriate assignment through the agent integration
The value appears when the line of reasoning stays steady enough for teams to follow across multiple executions.
How to Reduce AI Bias in QA Workflows
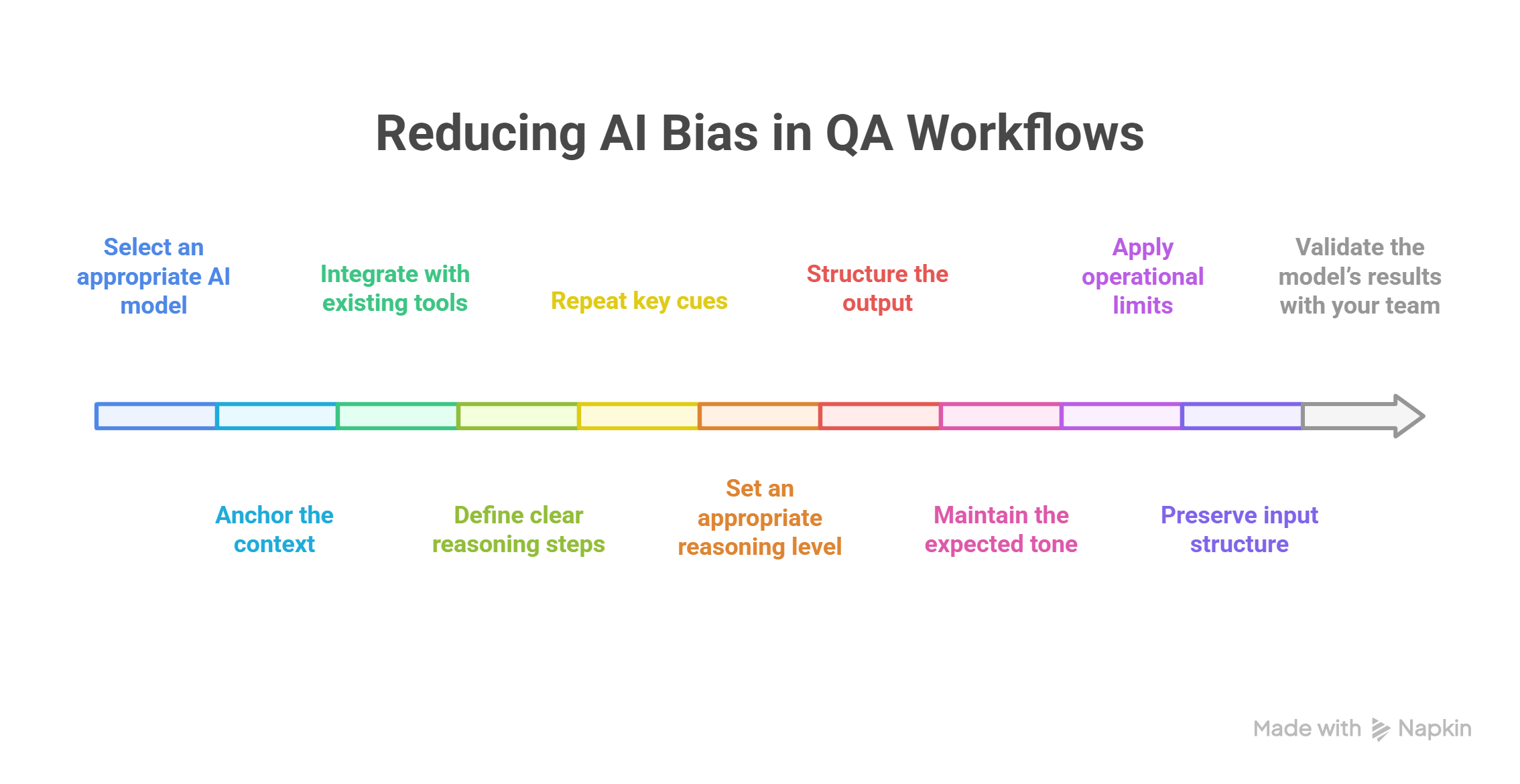
Use these reasoning-stabilization adjustments to keep the model aligned with real-world conditions and reduce the impact of social, data, and operational biases. To reduce AI bias, follow these steps:
- Select an appropriate AI model, considering reasoning depth, latency, and domain fit.
- Anchor the context, so the model interprets domain language, rules, and system constraints correctly.
- Integrate with existing tools, enabling outputs to connect with logs, repositories, monitors, or tickets.
- Define clear reasoning steps, guiding how the LLM reads, compares, and summarizes information.
- Repeat key cues, helping the model maintain consistency across executions.
- Set an appropriate reasoning level, avoiding shallow summaries or overly detailed responses.
- Structure the output, enabling answers to follow the required format for QA, documentation, or automation.
- Maintain the expected tone, so the model uses the appropriate level of formality, precision, and terminology for the domain.
- Apply operational limits, keeping the analysis focused and preventing drift into irrelevant details.
- Preserve input structure, so the model interprets signals consistently across environments.
- Validate the model’s results with your teams, checking accuracy, completeness, and alignment with real test evidence.
These elements help QA teams keep the model’s reasoning stable, readable, and aligned with real testing workflows.
How Abstracta Mitigates Bias in Real Workflows
At Abstracta, we combine technology and linguistics to understand how models interpret long requirements, regulatory documents, and the domain language behind complex systems.
That perspective guides how our agents operate inside Abstracta Intelligence, where prompt adjustments and defined reasoning steps help models keep a steady internal line across real delivery conditions.
In a recent project with an international bank, we tested an agent designed to generate user stories from extensive documentation. The results varied more than the team expected. Some runs produced stories with clear acceptance criteria and detailed system interactions, while others remained shallow.
These fluctuations reflected different forms of bias influencing how the model organized and prioritized information. After anchoring the agent’s context and clarifying its reasoning path, the depth and structure of the stories became consistent across runs, giving QA teams a stable foundation for review and integration into their workflows.
Our Approach
Teams often expect neutrality, but what they actually need is guidance that keeps the model’s reasoning consistent across similar conditions. We believe that the real objective shouldn’t be neutrality itself, but a level of consistency that allows teams to understand how a model reached a conclusion and whether that conclusion fits the conditions of the workflow.
Bias mitigation doesn’t remove the three forms of bias that appear in real workflows. Social tendencies remain, data imbalances still influence what the model prioritizes, and variations in reasoning don’t disappear entirely.
However, teams can use prompt refinement, contextual grounding, clear guardrails, and reasoning steps to achieve a level of stability that makes the model’s output reviewable, comparable, and reliable across executions.
If your team is working with AI-driven reasoning in QA or delivery, we can help you design structures that keep models stable and aligned with what your workflow actually needs. Let’s talk.
FAQs about Bias Mitigation and AI Neutrality

Why Is It Important to Avoid Bias in Prompt Engineering?
Avoiding bias in prompt engineering supports predictable reasoning in AI models and integrates fairness guidelines that help teams navigate cultural contexts without reinforcing subtle biases.
In QA workflows, this prevents reasoning drift and gives teams evidence paths grounded in real delivery needs rather than inherited assumptions.
What Is Bias Mitigation in AI?
Bias mitigation in AI reduces distortions from social tendencies, training imbalances, and variation in how the model organizes its reasoning. It increases stability so teams can interpret outputs with confidence using explicit fairness parameters when decisions shape quality or risk.
What Does ‘Chances of Bias Are Mitigated’ Mean?
Saying that chances of bias are mitigated means that prompt structures reduce the influence of social, data, and operational biases without eliminating them. The model still carries learned patterns, but its reasoning becomes stable enough for teams to compare outputs reliably across similar conditions.
What Is an Effective Technique in Mitigating Biases?
An effective technique in mitigating biases is refining prompts with explicit instructions, balanced examples, and gender neutral language to counter social, data, and operational influences.
This strengthens the model’s reasoning stability, helping QA teams evaluate outputs consistently across similar conditions.
Does Bias Mitigation in Prompt Engineering Give Neutral Results?
Bias mitigation in prompt engineering doesn’t produce neutral outputs because AI systems retain social, data, and reasoning tendencies learned during training. What it does provide is a narrower, more predictable reasoning range that QA teams can trace, compare, and audit reliably.
How Prompt Engineering Reduces Biased Responses in Real Workflows?
Prompt engineering reduces biased responses by structuring AI prompts with direct instructions, balanced context, validation examples, and reasoning steps, to shape how the model prioritizes information. These structures minimize drift across social, data, and operational biases, keeping outputs aligned with real delivery requirements.
How Training Data and Cultural Bias Affect AI Models?
Training data and cultural bias affect AI models by embedding patterns and cultural values that influence how information is ranked, interpreted, and reasoned about. Prompt engineers apply bias mitigation strategies to reduce these effects and support analysis aligned with workflow needs instead of inherited tendencies.
How Prompt Engineers Create Prompts That Avoid Bias?
Prompt engineers create prompts that avoid bias by setting explicit rules, defining limits, using diverse examples, using neutral phrasing with diverse, gender-neutral examples, and incorporating multiple perspectives when neccesary. These guardrails reduce the influence of social, data, and reasoning biases during decision-making tasks.
Why Validation Checkpoints Are Critical for Bias Mitigation in Prompt Engineering?
Validation checkpoints are critical in bias mitigation because they force the model to pause, verify constraints and ethical guidelines, and verify its reasoning process before generating a final answer. These intermediate controls reduce drift, detect biased patterns early, and keep the model aligned with the rules and limits defined in the prompt.
How Balanced Context and Direct Instructions Support Bias Reduction?
Balanced context and direct instructions support minimizing bias by giving AI models clearer boundaries during prompt design. This helps refine prompts so response patterns stay aligned with the task and avoid stereotypical associations. These constraints reduce ambiguity and help QA teams compare outputs reliably across changing operational conditions.
How We Can Help You
Founded in Uruguay in 2008, Abstracta is a global leader in software quality engineering and AI transformation. We have offices in the United States, Canada, the United Kingdom, Chile, Uruguay, and Colombia, and we empower enterprises to build quality software faster and smarter. We specialize in AI-driven innovation and end-to-end software testing services.
We believe that actively bonding ties propels us further and helps us enhance our clients’ software. That’s why we’ve forged robust partnerships with industry leaders like Microsoft, Datadog, Tricentis, Perforce BlazeMeter, Sauce Labs, and PractiTest.
We’ve seen teams cut debugging time by half and releases by a third.
Check out our solutions!
Let’s discuss what that could mean for you.

Follow us on Linkedin & X to be part of our community!
Recommended for You
Introducing Abstracta Intelligence

