Have you ever wondered if the test automation pyramid model could also be applied to optimize the performance testing strategy? In this article, we share an innovative take on the test pyramid in Agile. Specifically “the automation pyramid for performance testing”, to improve your holistic strategy for performance testing.

By Federico Toledo (Abstracta) and Leandro Melendez (Grafana k6)
The automation of various types of software testing has generated great benefits such as efficiency improvement, human error reduction, acceleration of testing processes, cost reduction, and increased test coverage.
In short, they have revolutionized the way we approach quality control in software development.
Understanding Performance Test Automation in Agile Development
Among the tests that need to be automated, load tests stand out for their importance in helping us prepare systems for critical moments of high demand. They allow us to understand how systems behave when accessed by many people concurrently, and thus prevent possible performance issues.
In agile contexts and agile teams, where applications are constantly evolving, it’s essential to underline the importance of maintaining performance automated test scripts.
The systems we test evolve and change as we run performance tests during software development iterations. Therefore, new features will be regularly released for testing, requiring new tests as well as the execution of existing ones, often organized within a comprehensive performance test suite. This will lead to the test code having to be maintained in the same way as the application code.
This is where performance test automation comes into play, considering different aspects such as its ease of preparation, maintainability, possibility of recurrent execution, etc.
Even so, we also find some of the same disadvantages of functional automation in performance testing when good practices are not followed. Some aspects are important to consider to create quality automation.
If we do not design and organize our automation properly, it can end up being counterproductive since the cost of maintenance will exceed the benefit of having those tests.
How to Automate Performance Tests Efficiently?

The automation pyramid model, or “Aztec Sacrifice Pyramid of Automation” (as Leandro calls it), provides guidelines for teams to optimize their testing efforts and results obtained from their automated tests, both functional testing and performance.
This strategy is useful for addressing performance testing in both waterfall and agile methodologies.
Next, we share a model that can serve as a guide when defining a performance testing strategy.
The Automation Pyramid Model Applied to Performance
Based on the famous Cohn pyramid for functional automated tests, both Leandro and Federico agree that the model, as explained with the triangle as a pyramid, applies to performance testing.
This model provides guidelines on prioritizing types of automation. How does it do it? While there are different versions and interpretations, it generally indicates that higher priority and abundance should be given to unit-level automation.
Then, to integration tests (or API or service tests), and in a lower priority category, automation at the Front End or GUI (Graphical User Interface) level, which we will call end-to-end, as they test the entire system from end to end.
Integration Testing Strategy
Integration tests
These tests are essential for validating that different modules or services used by your application interact correctly. They involve testing combined parts of the application to expose faults in the interactions and interfaces between integrated units.
Test Suite and Management
A comprehensive test suite supports both unit and integration tests, enabling developers and testers to verify functionality and performance across multiple layers of the application architecture.
Cohn Model & Performance Pyramid Model
In the following image, we show the equivalences between the Cohn model and the performance pyramid model. In it, we can see what would correspond to each level.
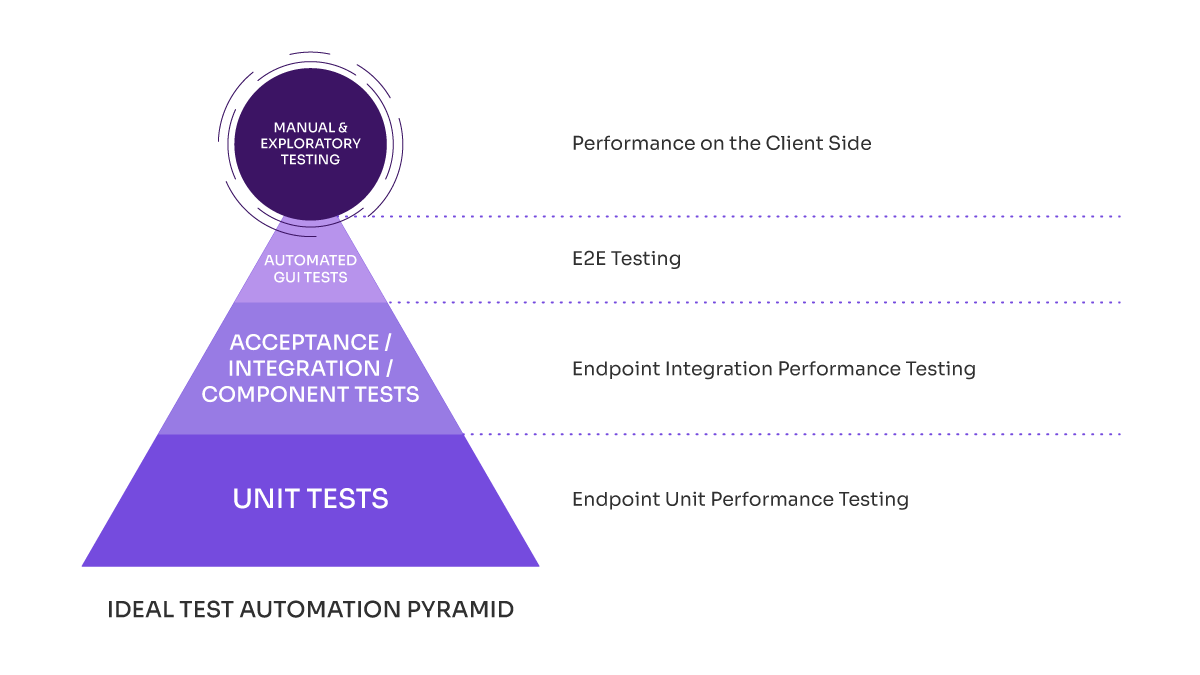
Next, we look at the advantages and disadvantages of each layer. As we move down the test pyramid towards the base, we can get:
- Cheaper API and unit testing: Easier to prepare, with less infrastructure.
- Easier to maintain so it can run more frequently (every day.)
- Tests can be performed earlier.
- Disadvantages: they are not conclusive about the actual metrics of the user experience.
As we move up the pyramid, we find:
- Load scenarios that require infrastructure and load similar to production.
- More expensive tests because they are harder to prepare and maintain.
- Better results, direct correspondence with metrics of people using E2E.
Later on, in this same article, we will go into more detail on each of the pyramid’s levels. As the model is based on a pyramid, Leandro calls it “the Aztec pyramid of automation sacrifices”.
Test Pyramid: Why Mention ‘Sacrifices’?
This is related to the idea that, just like in the time of the Aztecs, sacrifices take place at the top of the pyramid. Applying it to software, this is where most people try to automate excessively, end-to-end test types, which can be seen as a sacrifice.
Unfortunately, it is common to see organizations or teams have a strategy in which the quantities of automation, or test coverage, are opposite to what the pyramid proposes. This anti-pattern is commonly known as the ice cream cone model. But because of this, Leandro calls it the cone of sacrifices.
The strategy proposed by the automation pyramid indicates that unit automation should be prioritized, then integration tests, and, finally, minimize sacrifices at the top with end-to-end automation, instead of generating cones of sacrifices.
Test Automation Pyramid for Performance Testing, Each Layer in Detail

The idea of this pyramid is to serve as a reference when establishing the system’s performance testing strategy. This will be more or less applicable depending on the architecture. We can say that it is mostly applicable when there are microservices or at least a layer of SOAP or REST services.
Next, we will look more in-depth and detail at aspects of each of the layers we mentioned in the model. Starting from the base, where we find unit performance tests. Then, we will describe the integration of service tests, end-to-end tests, and finally, aspects of client-side performance.
Unit Performance Testing
The aim is to test each service individually in isolation, simulating a certain load on it. Preparing a test is extremely simple since it involves a single HTTP request.
Despite the automation approach, exploratory testing always plays a vital role in our agile testing strategy, allowing testers to apply their creativity and intuition. This approach helps to uncover defects that may not be caught by automation testing methodologies.
Here, we will always run the same test and compare the most recent results with the previous ones to observe if the response times show any significant degradation, to identify and monitor possible performance problems in the system.
When talking about end-to-end tests in load simulation, our load scenario and assertions are based on business objectives.
Effective management of test data is crucial for the accuracy and efficiency of performance tests. Properly managing test data helps ensure that each test can be performed consistently and can mimic realistic operational conditions.
How Many Users Do I Simulate When We Carry Out Unit Tests at The Service Level?
Especially when those tests will be executed in a reduced testing environment. The tests must have acceptance criteria (assertions) as tight as possible, so that, before the slightest degradation in the performance of that functionality and before any negative impact, a validation fails and signals the problem.
Usually, this is achieved by checking error rates, response times, and throughput (number of requests or requirements attended per second).
Common Issues in Unit Performance Testing
In the following graphs, we share a typical problem we want to avoid:
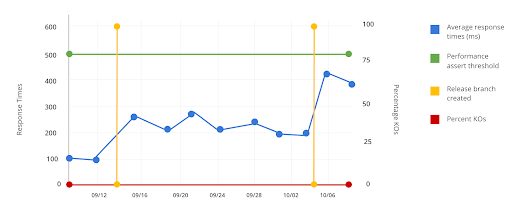
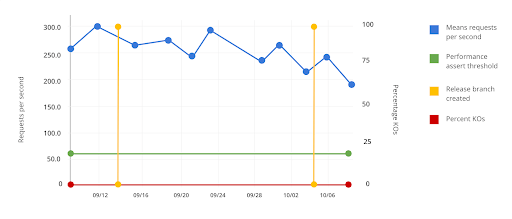
In the first image, we see that response times increase. In the second one, we notice a decrease in requests per second (RPS), but the test does not report an error or give an alert about this degradation because the acceptance criteria are not strict. The test verifies that the performance is above 60 RPS, so when the functionality decreases from 250 to 200, no one will pay attention to that.
To avoid these problems, we need the assertions to be stricter so that a degradation of this type makes the pipeline fail.
How to Define the Load and The Assertions?
What we need to do is to make certain executions in experimental mode, to be able to determine the load and assertions that we will set in our unit performance tests, in order to execute them continuously in our pipeline.
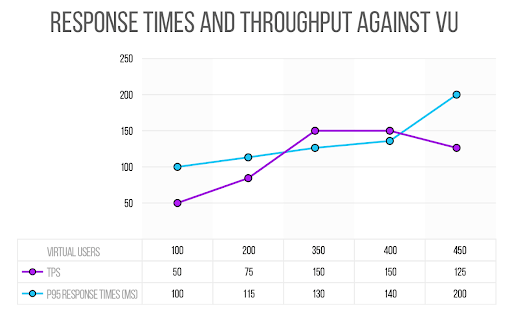
Let’s say our first test runs 100 parallel executions that result without errors, the response times are less than 100 milliseconds (ms), at least the 95th percentile, and the throughput is 50 RPS.
Next, we run the same test but with 200 RPS. Again, no errors occur, and the times are at 115 ms and the performance at 75 RPS.
Great, it’s scaling.
Identifying the Scaling Limits
If we continue on this path of testing, at some point we will reach a certain load at which we will see that we can no longer increase throughput.
Following this scenario, let’s imagine that we reach 350 parallel executions and we have a throughput of 150 RPS, with response times of 130 ms and 0% errors.
If we go over 400, the throughput remains at about 150 RPS, and with 450 in parallel, the throughput is even less than 150.
There is a concept called Knee point (knee, due to the break in the graph) that we would find at a certain point, which determines that we are saturating some bottleneck.
It is expected that the number of requests per second will increase when we increase the number of concurrent executions. If it does not happen, it is because we are overloading the system’s capacity.
This is the basic method to find the Knee point when doing stress testing when we want to know how much our servers can scale under the current configuration.
Setting Performance Benchmarks
Thus, at the end of this experiment, we come to define the scenario that we want to include in our pipeline, with the following assertions:
Load: 350 concurrent executions.
Assertions
- Less than 1% error.
- Response times P95 <130 ms + 10%.
- Throughput >= 150 RPS – 10%.
Next, the test that we will program to keep running frequently is the one that runs 350 concurrent executions. We expect it to have less than a 1% error with response times below 130 ms, with a possible margin of 10%, maybe 20%,
Last but not least, we have to check that the throughput is at least 150 RPS, also with a margin of 10%.
In this way, we can detect as early as possible when a change causes the system’s performance to decrease.
For all this to be valid, we need an exclusive environment for testing. In this way, the results become more predictable and are not affected by factors such as other people concurrently running other tasks.
Performance Testing on the Integration Tier

In these tests, we will be able to test several services at once to see how they affect each other’s performance. For this, we will take the same unit tests and combine them into a single concurrent scenario. If we already have the others prepared, setting up these tests should not be so complex.
Before continuing, we would like to clarify why it is important to test the same services in a combined way.
“Fallacy of Composition”
Testing the parts is not enough to know how the whole will behave. The whole must be tested to see how the parts interact.
As Jerry Weinberg taught us, good testing teams know that it is not enough to test the “parts” to know how the “whole” will behave, as the whole must be tested to see how the parts interact.
Therefore, we should complement unit tests with integration tests.
End-to-End Performance Tests
These are the classic performance tests in which we simulate the load we expect in the system (a certain number of people accessing concurrently) in an environment that replicates the conditions of the production environment. The scripts have to be prepared at the level of client communication (browser, mobile app, etc) and not at the service level.
The main objective of end-to-end performance tests is to identify possible bottlenecks, scalability issues, or performance degradation that may arise in real usage situations.
These tests usually involve simulating real people interacting with the application through multiple steps, such as browsing pages, filling out forms, and conducting transactions. Collecting data on response times, error rates, and other key performance indicators is essential for assessing system behavior under load.
They are, in short, a fundamental part of the quality assurance process, as they help an application to operate efficiently and effectively under production conditions, thus minimizing performance issues.
Client-Side Performance

In addition to the previous layers of the pyramid, which focus on the server side, we would like to remind you to never forget the client side or browsers. Problems on the client side that cause delays in the final experience can invalidate the optimization efforts made in the backend (the servers).
In the case of web applications, there are numerous tools available to assess performance from this perspective. Not only will they automatically tell you what issues are present on the site, but they will show you how to solve them. We share some of them:
- Lighthouse, as part of Google Chrome Developer
- Google PageSpeed Insights
- Website.io
- Yslow
In the case of Mobile apps, we recommend using Apptim, a tool that specializes in evaluating the performance of mobile applications.
These tools can be very useful to help your application operate efficiently and provide an optimal experience.
In addition, it’s important to mention that there exists the possibility of performing hybrid tests, as proposed by Marie Cruz in her article on browser performance testing. This strategy combines tools such as k6 browser and Google Lighthouse to get a complete view of your application’s performance from different perspectives.
The proposal for hybrid testing can be especially beneficial to identify problems both on the server side and on the client side.
Other Views of The Test Pyramid Model

Something good about models is that they allow analyzing different views that can be useful. In addition to what has been previously stated, we want to share other interesting aspects when analyzing the same model, which gives it more dimensions to consider.
Frequency of Executions
Let’s imagine another view of the pyramid, which refers to the frequency of executions that should be carried out at each testing level. This is especially important in modern projects that follow agile, continuous, or variations of the agile style.
The fundamental thing about this is to determine how frequently I can execute each type of test. This depends on how easy to prepare, code, and maintain these tests are, as well as, on the other hand, what information they provide me.
Therefore, the proposal is to execute the unit tests of the services frequently, perhaps in each build of the pipeline, as explained (by Federico) in this webinar and this post.
To see how services impact each other, we should occasionally execute tests where we combine several services, called integration tests.
Since up to here we do not know anything about what the user experience will be, we have to complement this with the classic load tests. They are much more complicated to prepare, but they are the only ones that help us reduce these risks.
The good thing is that if we frequently do unit tests and integration tests, we can probably reach this stage with less probability of finding serious problems or, at least, we have anticipated several of them.
Similar to what was explained in the previous pyramid, many organizations follow an inverted strategy and focus on executing load tests more frequently while performing very low amounts and executing unit tests infrequently.
Performance Testing Infrastructure
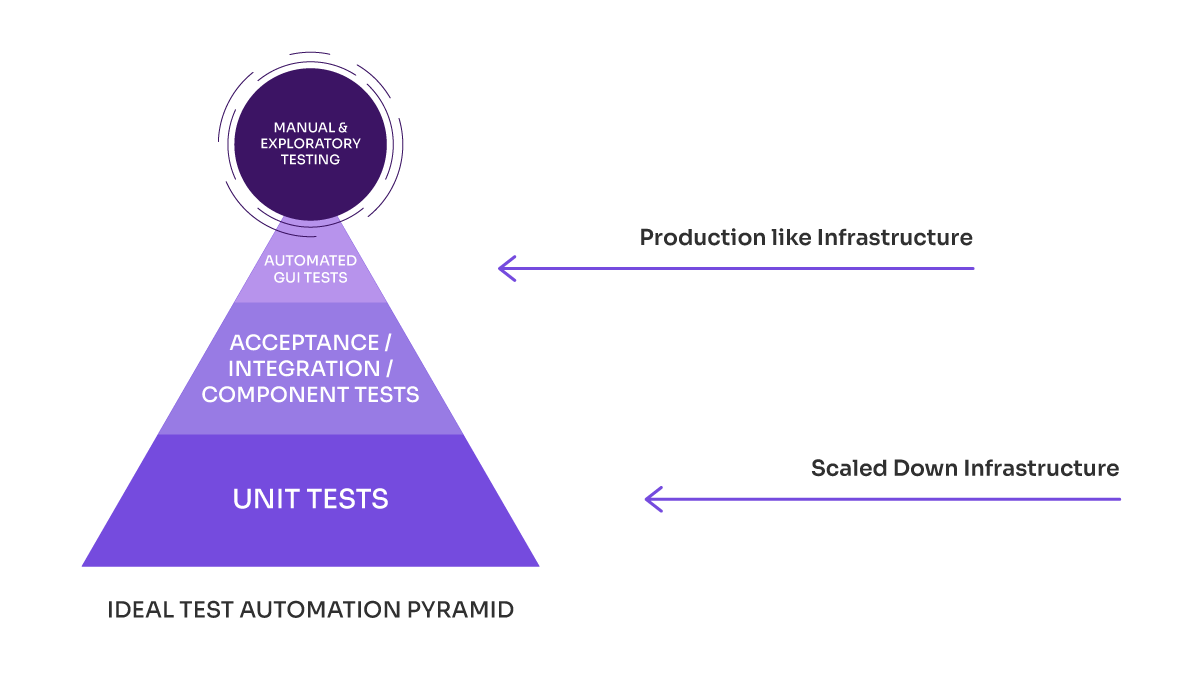
How many times have you also heard that we can only execute performance tests on infrastructure that is very similar to production?
We believe this statement applies mostly to the tests that correspond to the highest layer of the pyramid, that is, to the end-to-end tests that will allow us to know the response times that those who access the system will get.
On the other hand, it is worth clarifying that we can execute performance tests on lower-power infrastructures, such as testing or development environments, and get very useful results from those executions.
What must be kept in mind is that the results should not be extrapolated. In other words, if I execute in a test environment, it is not safe to assume that in production, where the infrastructure has double the power, response times will be halved.
Running unit and integration tests in reduced environments like testing or development brings many advantages. Some errors and optimizations can be attacked despite not having environments like production.
Performance tests always yield valuable results in all scenarios.
In particular, the advantage of running these tests in reduced (scaled down) environments is that we will be able to stress the system, to analyze how it behaves near its limits, with lower loads. This implies lower costs of test infrastructure or load simulation tool licensing. Preparation and management will be easier, and results can be obtained earlier.
Would you apply the pyramid model to your performance tests? What did you think of this topic? What do you think of the automation software testing pyramid applied to performance?
Do you have other tips or ideas on the subject to share? We would love to hear your opinion and experience!
In need of help with Test Automation or Performance Testing services? Don’t miss this article! Raising the Level: Getting Started With a Software Testing Partner.
We are quality partners! Learn more about our solutions here! Contact us to discuss how we can help you grow your business.



