In part one of this three-part series on code analysis, we explore technical debt and the means for tackling it
Code quality is often said to be an internal attribute of quality since the user never lays eyes on it. But, there comes a time when this attribute of quality goes from being internal to external, which happens precisely when the code must be changed, yet it takes much longer than it should and so, the user suffers while they wait.
In order to guarantee correct code quality, you can use different static code analysis tools, such as SonarQube, Codacy, Kiuwan, etc. Among the checks on code quality that they carry out are:
- Duplicate code
- Lack of unit tests, lack of comments
- Spaghetti code, cyclomatic complexity, high coupling
- Size of source files
- Size of methods
- Not conforming to code standards and conventions
- Known security vulnerabilities
These tools allow for automatic static analysis of source code, looking for patterns with errors, bad practices or incidents. In addition, many of them are capable of calculating a metric known as “technical debt.”
What is Technical Debt?
The concept of technical debt is an analogy to explain something as complex as the need to do “refactoring” or why invest in the “code quality.” When coding under pressure and with the need to deliver something quickly, often times, many good practices, like unit tests, etc. go by the wayside. When they do, it is said that you are acquiring a debt with the software: Today I release the software without having done all these quality practices, and then I am left with the debt of doing them at some point in the future (when I finally have time).
[tweet_box design=”default” float=”none”]The problem associated with technical debt is that, like any debt, it accrues interest.[/tweet_box]
When the developer is finally ready to pay that debt, he or she will have to take the time to get back into the mind frame they had when they were developing that functionality. Thus, in the end, the developer will have invested more time going back, tweaking the code than if they had just developed using good practices in the first place when all was fresh in their mind.
That is why you want to identify any problem in the code quality as soon as possible, in order to pay the debt as soon as possible, without having to pay too much interest.
Technical debt is measured in hours. Code analysis tools have a reference table, and depending on the type of incident, they provide an estimation of how much time should be spent to resolve it. By making the weighted sum based on that table, they manage to estimate the number of days and hours that should be invested to be able to pay the debt.
Code analysis tools generally enable us to categorize the incidents detected according to their severity. This is how there will be issues of blocking, high, medium, and low severity. A strategy can then be established by basing the quality thresholds (also known in some tools as quality gates) on the number of issues that are allowed for each category.
To better understand these concepts, it is useful to review the SonarQube website. There they have analyzed many open source projects, where you can see what type of incidents are detected, how they are categorized, and what is the resulting calculated technical debt.
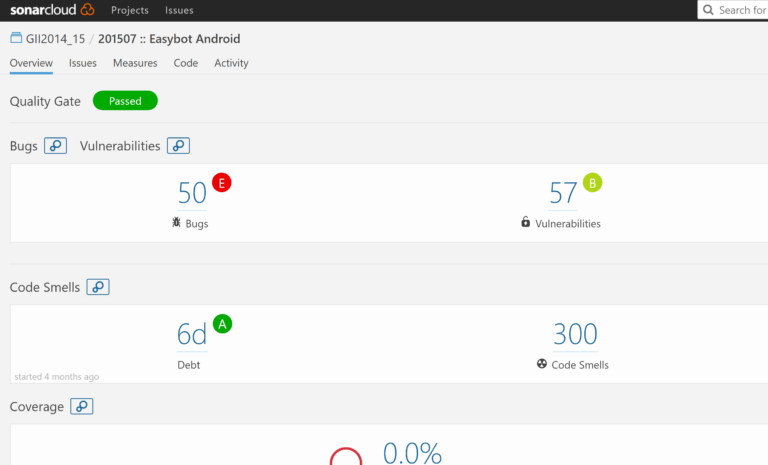
(In the example I took from the SonarQube site, this project has a debt of 6 days.)
In the particular case of SonarQube, by defining “quality gates” it is possible to mark acceptable thresholds in the development process, which can be determined based on different metrics. The quality gates definition can also help answer questions such as:
- Are there are any new issues that are critical or blocking?
- Is the code coverage of unit tests for the new code greater than 80%?
- Are there more than 10% duplicate lines?
- Are there any known security vulnerabilities?
You can start by setting flexible thresholds (quality gates), and throughout the project, try to set more stringent targets. For example, you could start by demanding 100% coverage of public methods, and then increase to have 100% of the lines of code.
It’s important to emphasize that coverage at the code level does not guarantee that the software is bug-free, not even the most demanding one. Sometimes it doesn’t make sense to propose a 100% coverage of the lines of code. This is due to, more than anything, that some code could be generated automatically by a component or tool, and also because not all modules of the system will have the same criticality. In this sense, it’s possible to define different quality gates for different modules. You can also adjust the rules on which the static analysis is based.
Do you have this type of analysis in your delivery pipeline?
Ready for part two? We share a tutorial for analyzing code with SonarQube!
Recommended for You
5 Benefits of Adopting Agile in Your Software Project
Debugging in Production with OverOps


