Average response time, standard deviation, and percentiles 90, 95, and 99 are the top performance testing metrics. Use them to understand system health and support reliable growth.
What if the real risk in performance testing isn’t the code, but the way you read the numbers?
Performance testing metrics that look fine on paper can still hide slowdowns, bottlenecks, and user frustration, as they define how people experience your system
The issue comes up when your team doesn’t understand what each metric means or represents. Wrong conclusions follow, leading to performance degradation instead of consistent performance.
Misread your metrics, and stability is an illusion—users are already slipping away.
This post highlights average response time, standard deviation, and percentiles 90, 95, and 99, in detail, showing how to read them for reliable growth. We also explore additional metrics that give a fuller view of system performance.
Get clear, actionable insights from your performance metrics.
Talk to our experts and turn data into reliable growth.
The Importance of Analyzing Data as a Graph
The first time we thought about this subject was during a course that Scott Barber gave in 2008 (when we were just starting up Abstracta), on his visit to Uruguay. He showed us a table with values like this:

He asked us which data set we thought had the best performance, which is not quite as easy to discern as when you display the data in a graph:
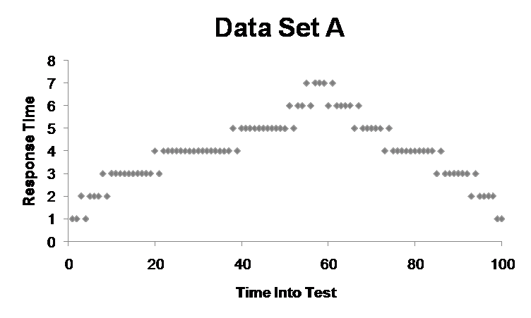
In Set A, you can tell there was a peak, but then it recovers.
In Set B, it seems that it started out with a very poor response time, and probably 20 seconds into testing, the system collapsed and began to respond to an error page, which then got resolved in a second.
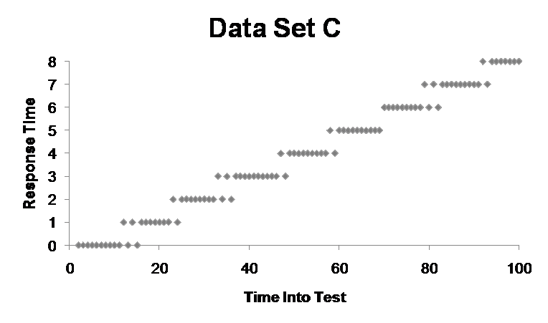
Finally, in Set C, it’s clear that as time passed, the system performance continued to degrade.
Barber’s aim with this exercise was to show that it’s much easier to analyze information when it’s presented in a graph. In addition, in the table, the information is summarized, but in the graphs, you can see all the points. Thus, with more data points, we can gain a clearer picture of what is going on.
Interested in data analysis? Keep learning here: Data Observability: What It Is and Why It Matters.
Understanding Key Performance Testing Metrics

Okay, now let’s see what each of the metrics for performance testing means as a key part of your performance testing process. Evaluating key performance indicators helps confirm that your tests align with business objectives.
Average Response Time
Average response time is the mean time a system takes to respond to a request during performance testing. To calculate the average, simply add up all the values of the samples and then divide that number by the quantity of samples.
Let’s say we do this, and our resulting average peak response time is 3 seconds. The problem with this is that, at face value, it gives you a false sense that all response times are about three seconds, some a little more, and some a little less, but that might not be the case.
Imagine we had three samples, the first two with a response time of one second, the third with a response time of seven:
1 + 1 + 7 = 9
9/3 = 3
This is a very simple example that shows that three very different values could result in an average of three, yet the individual values may not be anywhere close to 3.
Fabian Baptista, co-founder and Chief Innovation Officer at Abstracta, made a funny comment related to this:
“If I were to put one hand in a bucket of water at -100 degrees Fahrenheit and another hand in a bucket of burning lava, on average, my hand temperature would be fine, but I’d lose both of my hands.”
So, when analyzing average response time, it’s possible to have a result that’s within the acceptable level, but be careful with the conclusions you reach.
That’s why it is not recommended to define service level agreements (SLAs) using averages; instead, have something like “The service must respond in less than 1 second for 99% of cases.” We’ll see more about this later with the percentile metric.
Don’t miss this Quality Sense Podcast episode about why observability is such relevant in software testing, with Federico Toledo and Lisa Crispin.
Standard Deviation
Standard deviation is a performance testing metric that shows how much response times vary around the average. If the value of the standard deviation is small, this indicates that all the values of the samples are close to the average, but if it’s large, then they are far apart and have a greater range.
To understand how to interpret this value, let’s look at a couple of examples.
If all the values are equal, then the standard deviation is 0. If there are very scattered values, for example, consider 9 samples with values from 1 to 9 (1, 2, 3, 4, 5, 6, 7, 8, 9), the standard deviation is ~ 2.6 (you can use this online calculator to calculate it).
Although the value of the average as a metric can be greatly improved by also including the standard deviation, what’s more useful yet are the percentile values.
Understanding key performance testing metrics is the first step.
Let’s apply them together to deliver measurable business value.
Book a meeting
Percentiles: p90, p95, and p99
Percentiles in performance testing are metrics that show the value below which a certain percentage of response times fall.
Understanding them is crucial for accurate analysis during test execution, since they reflect how systems behave when many users interact simultaneously. Percentiles reveal performance under varying loads, helping teams identify bottlenecks and optimize resource allocation.
Let’s break down what percentiles like the 90th percentile (p90), p95, and p99 mean and how they can be used effectively in performance tests.
What Are Percentiles?
A percentile is a performance testing metric that shows the value below which a certain percentage of results fall. It reveals how response times are distributed across all samples. The percentile rank is another metric that indicates the relative position of a given value within that distribution.
The 90th Percentile (p90)
The 90th percentile (p90) indicates that 90% of the sample values are below this threshold, while the remaining 10% are higher. This is useful for identifying the majority of user experiences and boosting that most users have acceptable response times.
The 95th Percentile (p95)
The 95th percentile (p95) shows that 95% of the sample values fall below this threshold, with only 5% above it. This provides a more stringent measure of performance, enabling nearly all users to have a good experience.
The 99th Percentile (p99)
The 99th percentile (p99) represents the value below which 99% of the sample falls, leaving just 1% as outliers. This is particularly valuable for identifying outliers and making it possible that even the worst-case scenarios are within acceptable limits.
Why Use Multiple Percentiles?
Analyzing multiple percentile values, such as p90, p95, and p99, provides a more detailed view of system performance. Tools like JMeter and Gatling include these in their reports, allowing teams to calculate percentile scores using different methods. This comprehensive approach helps in identifying performance bottlenecks and understanding how the system behaves under various conditions.
Complementing Percentiles with Minimum, Maximum, and Median Metrics
Percentiles provide more context when combined with metrics like minimum, maximum, and median values. For example:
- p100 (Maximum): the highest observed value, since 100% of the data is at or below this point.
- p50 (Median): the middle value, with half of the data below and half above.
Establishing Acceptance Criteria
Teams often use percentiles to establish acceptance criteria. For instance, setting a requirement that 90% of the sample should be below a certain value helps in ruling out outliers and enabling consistent system performance. This is particularly useful in identifying issues related to memory utilization and other critical performance aspects.
By focusing on the percentile score, teams can make more informed decisions and optimize their performance tests to achieve better results.
Leading a growing organization? Turn complex performance data into business insights.
Partner with us on Performance Testing Services!
Beyond the Core Metrics: Backend, Frontend, and System Behavior Insights
While average response time, standard deviation, and percentiles are the cornerstone metrics for understanding overall system performance, they provide a high-level view that doesn’t always reveal the root causes of performance issues.
To dig deeper, it’s important to analyze additional metrics that focus on the backend, frontend, and overall system behavior. For long-term reliability, incorporating endurance testing helps evaluate how the system performs under sustained load conditions. Let’s explore these key metrics.
What Are Backend Metrics?
Backend metrics are performance testing measures that focus on server-side infrastructure. They show how requests are processed, resources managed, and whether the system maintains efficiency under load.
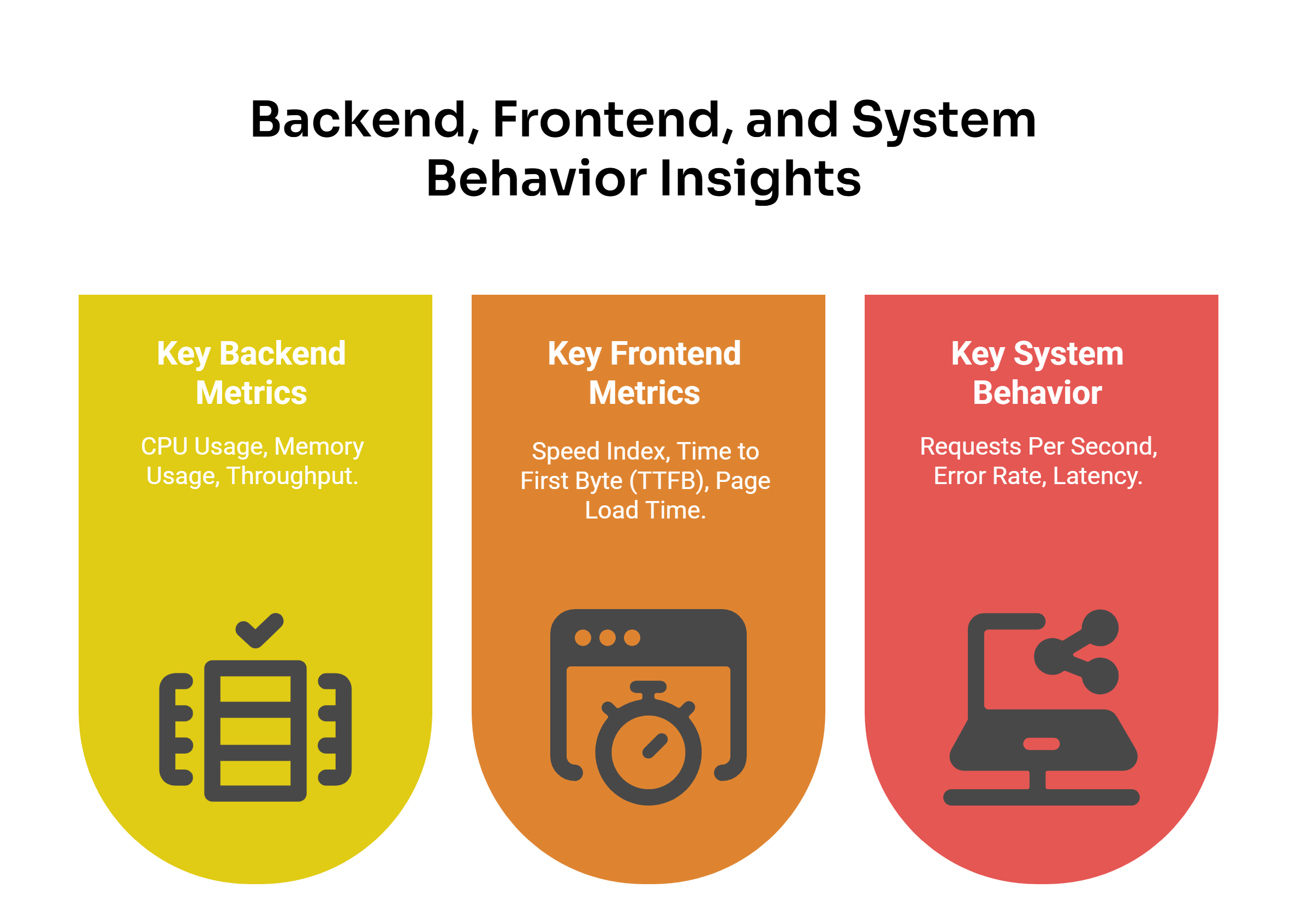
Key Backend Metrics
- CPU Usage: Tracks how much processing power is being used by the server. High CPU usage during peak loads can indicate bottlenecks that need to be addressed.
- Memory Usage: Monitors how much memory the server is consuming, helping to identify inefficiencies or potential overloads.
- Throughput: Measures the number of requests the server can handle over a specific period, helping to validate whether the system can scale to meet increasing user demands.
Backend metrics like CPU utilization and memory usage, which fall under the broader concept of resource utilization, provide insights into how efficiently the server is using its resources.
Tracking issues such as slow response times can reveal delays caused by database queries, API calls, or other backend processes. Similarly, monitoring failed requests is essential for identifying critical errors that could disrupt the system’s ability to process user actions effectively.
What Are Frontend Metrics?
Frontend metrics are performance testing measures that focus on the client side of the system. They show how fast the interface loads and responds, helping improve website performance and deliver a seamless user experience.
Key Frontend Metrics
- Speed Index: Assesses how quickly the visible parts of a web page are rendered, providing a clear indicator of perceived performance.
- Time to First Byte (TTFB): Evaluates the time it takes for the browser to receive the first byte of data from the server, which can highlight delays in server response.
- Page Load Time: Monitors the total time it takes for a page to fully load, including all assets like images, scripts, and stylesheets.
Analyzing the loading process helps identify delays that could significantly impact the user experience and have a direct effect on customer satisfaction. For example, making sure a web page can load completely without interruptions is critical for maintaining a smooth user experience. By focusing on client side performance testing metric, teams can identify issues like slow rendering or excessive JavaScript execution that may degrade the user experience.
What Are System Behavior Metrics?
System behavior metrics analyze how the entire system reacts under different conditions, such as high traffic or prolonged usage. They provide a holistic view of performance and help identify patterns that could lead to potential issues.
Key System Behavior Metrics
- Requests Per Second: Quantifies the number of requests the system can handle, helping to evaluate its capacity under varying loads.
- Error Rate: Tracks the percentage of failed requests, which is critical for identifying issues that could disrupt the system’s functionality.
- Latency: Calculates the time it takes for a request to travel from the client to the server and back, providing insights into potential delays in the system.
Analyzing user traffic patterns helps teams understand how different load levels impact the system, enabling better capacity planning and resource allocation. Identifying issues like memory leaks is also crucial for maintaining long-term stability, as these can lead to degrading performance over time.
Overall, by combining backend, frontend, and system behavior metrics with core metrics like average response time, standard deviation, and percentiles, you can gain a deeper understanding of your system’s performance. As you analyze them, it’s important to keep in mind certain considerations to avoid common pitfalls and misinterpretations. Let’s explore these in the next section.
Downtime is costly, and scaling companies can’t afford blind spots.
Protect your growth—act on performance metrics today!
Partner with us to build reliability at scale.
Careful with Performance Testing Metrics

Before you conduct performance testing or analyze your next software performance testing results, make sure to remember these key considerations:
1. Avoid Averages
Never consider the average as “the” value to pay attention to, since it can be deceiving, as it often hides important information.
2. Check Standard Deviation
Consider the standard deviation to know just how useful the average is, the higher the standard deviation, the less meaningful it is.
3. Use Percentile Values
Observe the percentile values and define acceptance criteria based on that, keeping in mind that if you select the 90th percentile, you’re basically saying, “It’s acceptable that 10% of my users experience bad response times”.
If you are interested in learning about the best continuous performance testing practices for improving your system’s performance, we invite you to read this article.
4. Overall System Health
Understanding metrics like server CPU capacity utilized and memory usage in certain cases examines system performance and provides insights into how efficiently the system is processing requests.
What other considerations and performance issues do you have when analyzing performance testing metrics? Let us know!
Looking for a Free Performance Load-testing Tool? Get to Know JMeter DSL, one of the leading open-source performance testing tools for Java and .NET developers.
FAQs About Performance Testing Metrics

What Are the Examples of Performance Metrics?
Examples of performance testing metrics include performance metrics that measure performance bottlenecks against business objectives and customer satisfaction through detailed test results. These critical values track performance trends to help organizations detect issues early, optimize system performance, and improve stability.
What Is KPI in Performance Testing?
Key performance testing metrics define key performance indicators that evaluate system performance and compare results against user expectations through the performance testing process. These measures enable consistent performance by aligning system efficiency improvements with insights from a performance testing tool.
What Does 95th Percentile Mean in Performance Testing?
In performance testing, the 95th percentile reflects the performance degradation point where average response time, minimum response time, and maximum response time show outliers. It highlights potential risks during peak hours and aligns with performance benchmarks to establish precise metric measures for optimization.
What Is P99 in Performance Testing?
P99 represents the threshold used to identify bottlenecks where virtual users test the system’s ability to handle concurrent users at scale. It is commonly applied during scalability testing to validate the system behavior under the maximum number of conditions and volume testing.
What Are the Common Categories of Performance Metrics?
Categories of performance metrics include memory usage, memory utilization, and memory leaks as server-side metrics combined with client-side and software testing metrics. These classifications describe system behavior and highlight critical metrics to evaluate software under different operating conditions.
Which Server-Side Metrics Best Predict Scalability Issues?
Server-side metrics such as CPU utilization, processing power, and server-side infrastructure help predict scalability issues, tracking high CPU usage and overall resource utilization. Monitoring processing requests reveals degrading performance while streamlining system reliability under heavier loads.
How Do Client-Side Metrics Like TTFB and Speed Index Compare?
Client-side metrics like TTFB and Speed Index are compared based on what they measure: TTFB reflects server response time, while Speed Index shows how quickly visible content loads. Both highlight delays such as slow response times and affect the perceived performance that contributes to a smooth user experience.
How Is Error Rate Calculated and What Thresholds to Use?
Error rate is calculated by dividing failed requests or failed transactions by total processing requests, which measures system performance under varying conditions. Thresholds are tuned to improve system efficiency, helping software perform reliably during test execution in a consistent test environment.
How Can AI Agents Support Performance Testing?
AI agents can augment performance testing by analyzing test scenarios, test execution, and load testing metrics to deliver actionable insights at enterprise scale. They assist performance engineers in identifying performance bottlenecks, aligning system’s ability with business objectives, and supporting enterprise systems sustain seamless growth. Take a closer look at our AI Agent Development Services.
What Mix of Metrics Should I Monitor for Load vs Stress Tests?
Load testing and load testing metrics measure how much data flows through systems, while stress testing highlights failure thresholds. Monitoring identifies performance bottlenecks in realistic test scenarios using a testing tool and helps refine capacity planning.
How We Can Help You
With over 17 years of experience and a global presence, Abstracta is a leading technology solutions company with offices in the United States, Chile, Colombia, and Uruguay. We specialize in software development, AI-driven innovations & copilots, and end-to-end software testing services.
We believe that actively bonding ties propels us further. That’s why we’ve forged robust partnerships with industry leaders like Microsoft, Datadog, Tricentis, Perforce, Saucelabs, and PractiTest, empowering us to incorporate cutting-edge technologies.
By helping organizations like BBVA, Santander, Bantotal, Shutterfly, EsSalud, Heartflow, GeneXus, CA Technologies, and Singularity University we have created an agile partnership model for seamlessly insourcing, outsourcing, or augmenting pre-existing teams.
Visit our Performance Testing Services page!
Contact us to improve your system’s performance.

Follow us on Linkedin & X to be part of our community!
Recommended for You
AI for Business Leaders: Strategic Adoption for Real-World Impact


How Shutterfly Masters Continuous Performance Testing
How Shutterfly masters continuous performance testing by “adjusting the belt tight” Picture this, you are the owner of an e-commerce website and you want to be sure that its excellent customer experience doesn’t deteriorate over time with the introduction of new functionalities and that your…

Shift-Left Testing in the Enterprise and the Case for Open Source
Why continuous testing and open source are a perfect match I recently visited the offices of CA Technologies (one of Abstracta’s partners) in Santa Clara, where I had the chance to discuss shift-left testing, continuous testing, and why and how to turn to open source…


