Looking to create a performance test plan? Here are some things to consider before you decide to simulate load.
When talking about how to make a performance test plan, I am not referring to a document, but rather what we are going to execute in the time that we have allocated for testing so that we are able to answer our questions about our system’s performance after having run the fewest executions possible.
First of all, it is necessary to know what kind of questions we are going to answer with the results from the tests. Here are some of the most common examples:
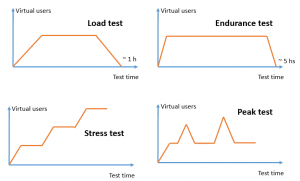
- Stress test: What is the maximum number of concurrent users that the system supports with an acceptable user experience? What is the breaking point?
- Load test: Given the current system load scenario, how will the application behave? What opportunities for improvement do we see for that expected scenario?
- Endurance test: How will the system work after running for some time (say, after a full day)? (In some cases, this involves taking actions like restarting the server every night until finding a definitive solution for some leak present in the system. Sounds terrible, but it could happen!)
- Peak test: If my normal system works properly and there is a peak in stress (the casuistry makes it so that many more requests match at the same time than normal, meaning the response times may become worse than acceptable), then how fast does the system recover?
In any situation, there is always one question that we will always have regarding the performance test: What are the main bottlenecks? And then, how do I solve these potential problems or limitations? We may even have questions like:
- Is my team prepared for something like this happening in production or do I need to learn something else?
- How quickly do we find solutions to performance problems?
- What physical resources do I have available or how difficult would it be to obtain them?
With these questions, we already have much to do; it is often necessary to check system access logs to get an idea of the number of users connecting daily, or we have to make estimates and inquiries about how many users we expect to have. When designing the test, this is refined much more since it is necessary to investigate what each of these users do (what test cases, what data, etc.).
What I want to focus on in this post is: Once I know what the expected load is, how do I run that load scenario?
Performance Test Plan: How Many Concurrent Users Do I Run?
Something that I have repeated many times (so many times that it must be true!): If we design/define our load scenario with X amount of users, we can’t start by running a test that simulates that full amount of concurrent users. If we do that, as experience tells us, surely several problems will appear all at the same time and we won’t know from where to start — hence, the idea of applying an incremental, iterative methodology for our performance test plan.
It’s iterative because different test iterations are executed and incremental because we start with a reduced number of concurrent users, solving the problems that arise and increasing the concurrency as we go.
Example: Load Test
We’ll consider a load test in our first example where the objective of the test is to analyze if the system supports 1,000 concurrent users.
- First test: 1 user without concurrency. This can serve as the baseline for later comparisons; it can be with 1, 5, 10, or more, but it has to be something extremely lower than what is actually expected in the system).
- Second test: 200 concurrent users (or 20% of the expected load). Here, you can get a lot of information, especially about just how difficult it will be to complete the test on time and in what way.
When executing these initial tests, we will solve the heavier problems and the default configurations (connection pools or Java heap size for example), and we will have an idea of how to scale the system by comparing the response times to the baseline. Once the analysis and troubleshooting are completed, this test is run again and again until acceptable times are obtained.
Depending on how tight those results are, we will decide whether the third test will be 40% (to continue with increments of 20) or if we go with 50% of the load (thinking about going to 75 and 100). On the other hand, if the system responds very well, we may be encouraged to go straight to much more. In any case, what we want to have at the end is a graph that shows us the response times obtained with each test (with each percentage of the expected load), and thus we can see how the system evolved thanks to our work.

In this example graph, we see how different tests were performed increasing the load by 20%. In addition, it is easy to observe that the tests were repeated until reaching the SLA expected in each case, and right after reaching it, the next step was taken.
Example: Stress Test
As a second example, imagine that we want to find the breaking point of the system with a stress test. For that, we want to execute different tests with different amounts of users, analyzing if increasing the concurrency continues to increase throughput. If increasing the concurrency does not increase transactions per second, that indicates that we reached the breakpoint since it is saturating the system at a certain point without scaling.
If we start running tests with random numbers of users, it’s going to be like a blindfold over our eyes and we’ll lose a lot of time. What we consider to be the best strategy is to run a test that we could call an exploratory performance test, since we would run it to get an initial idea of where that breakpoint is. For this, we run an incremental test from 0 to X, where X is a large number of users (say 1,000 to consider a single load generator) and we believe that breakage has to be in that range.
What can be done in any load simulation tool is run the test to establish a uniform ramp-up during the test time — that is, if we want that test to last one hour, we set up the test to start with zero concurrent users, and after one hour, it has 1,000. Here, we will be able to have a first approximation to see when the throughput of the system is degraded. If we observe that it is around 650 users, we can begin to refine, running specific tests for this aim.
For example, we could run a test with 500, another with 600, and another with 700. If the test of 700 users actually has less throughput than 600, we’ll have to refine and execute one with 650, and so we continue with the midpoint, to improve accuracy.
Example: Endurance Test
For an endurance test, I would say run a constant load that is between 50-70% of the load supported by the system under acceptable conditions. A smaller load could also serve us in this case too, it all depends on how complex it is to prepare the test data in order for it to run for many hours.
Generally, these tests are executed after the stress or load tests have been completed to try to identify other types of problems (memory leaks, hanging connections, etc.). If you have the time, data and what is necessary for this, you could increase the loads that are used for the tests, running them on a prolonged basis.
Example: Peak Test
For a peak test, as we said before, the idea is to see how much it taxes the system to recover after a peak occurs. If there is a peak then does the system respond properly or does it get hang? At 10 seconds, does it recover? In two hours? Or what? For this, it is necessary to know the breakpoint of the system, to be able to prepare a test that is below that threshold, and generate a peak by raising the load for a period of one minute, for example, and then lowering it back.
The incremental approach that can be applied here is in the peak itself. You could start by experimenting with small peaks (short duration or low load) and then study how the system reacts to larger peaks. In any case, this is something that should be modeled based on a study of the behaviors of the users, especially based on the access logs that you may have.
Conclusion
How you make a performance test plan depends on the specific type of tests you’ll run based on the particular questions about your system that you want to answer, but they all have one aspect in common: We want to reduce the number of tests that we execute, optimizing the cost and benefit of testing. For this, the idea is to follow an iterative, incremental approach (for load, endurance, and peak tests) and one of refinement (for stress tests).
What is your take on this? Let me know about your experiences below!
Looking for help with your performance testing? Our team of over 100 quality engineers can help! Contact us today.
Recommended for You
When is the Best Time to Start Performance Testing?
Apptim Review: Mobile Performance Testing Tool



