In load tests we simulate the workload that an application will have in production, counting the concurrent users accessing the application, the tests cases that will be executed, and the frequency of executions by users, among other things.
The concept of workload or load scenario is defined as a mix of the system’s expected load at a given time (during daily operations, at peak hours, on the system’s day of most use, and so on).
When we prepare a performance test, we design a workload or load scenario using simplifications in order to improve the cost/benefit ratio. This is to say that, if we were to achieve an identical simulation to what the system will receive in production, we would end up with such an expensive test that it would not be worth it. The benefits may not be worth the costs and the results may even be obtained after it’s too late!
Our co-founder, Federico Toledo, submitted his research to the 2014 Modelsward, as part of his Ph.D. project, where one of the main contributions is the extension of the standard UML profile for testing, defined by OMG, and called UML-Testing Profile. The proposal adds useful concepts to the definition of performance tests, which include the possibility of modeling workloads.
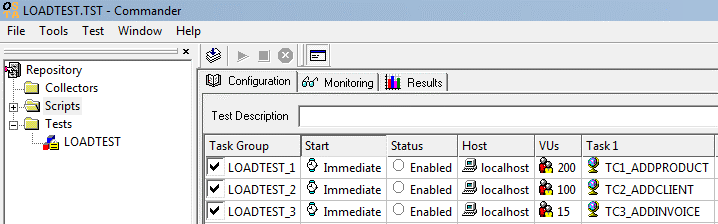
To view an example of a load scenario defined directly in a load simulation tool (which is in fact what we want to model in a UML diagram), take a look at the image below. It shows the OpenSTA console, and an example test defined with three tests cases (TC1_AddProduct, TC2_AddClient, and TC3_AddInvoice). These are executed concurrently, one with 200 concurrent users, another one with 100, and the other with 15. The execution of all these tests cases as a whole, and concurrently, simulates the reality of the system supposed.
When Federico concluded his presentation from the academic perspective, someone asked him why he did not consider stochastic processes, and modeling system’s users as a href=”http://en.wikipedia.org/wiki/Poisson_process”>Poisson process.
I find it interesting to find out why it is typical that simulation tools are not meant for this:
- We want tests that can be repeated. There will never be two executions that are exactly the same. However, we must try to reproduce identical situations. For instance, if we execute this test, we will find an opportunity for improvement. Following that change, we will want to verify if it was actually an improvement, how much the performance has improved, and so on. We should try to execute the same test again. When we execute a test with a variable factor (based on probability) we will lose that possibility.
- We want to improve the cost/benefit ratio by simplifying reality, without losing any realism, and with costs that are not exceedingly high. How much more would it cost us to define the mathematical model and make sure it is valid?
- We want clients to be capable of defining and understanding tests. It is hard for someone knowledgeable in the business and about the application to make estimates on the number of invoices to be issued in an hour or more, and it is even harder when we start considering mathematical concepts, in which case we would be adding complexity when it comes to defining and designing a test.
So, after giving it a lot of thought, we are still convinced that this approach for workload testing is the best concerning cost and benefit analysis.
What is your view on this subject? We would like to hear about your experiences as you apply this approach to your own workload testing practice.
Leave your comments below!
Recommended for You
How Soon is Too Soon to Carry Out Performance Tests?
Types of Performance Tests


