BDD is a development strategy, and even if you do not follow this practice, we find it beneficial to use Cucumber (or a similar tool) since it “forces you” to document your automated tests before implementing them. It’s fundamental that these tests be made clear to a user who does not know the behavior of the described functionality and that they be maintainable to reduce the costs of making changes in the test steps.
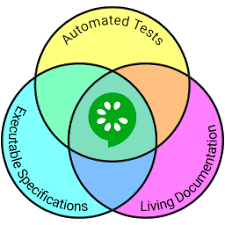
This image by Cucumber reflects the idea of combining automated tests, having a living documentation, and at the same time, still having specifications that are executable. All of this is thanks to the approach of using a tool like Cucumber.
To work with Cucumber, you will need these files:
- Feature file: text file where the acceptance criteria are written in Gherkin format. These acceptance criteria could be seen as the tests we are going to prepare.
- Step Definition: files in the chosen programming language where Cucumber will be able to associate what actions to execute associated with each step of each acceptance criterion defined in the different features.
- Others: Then, depending on what level we do the tests, other files may be needed. For example, if we are doing this at the level of the presentation layer, the Web GUI, then we are going to use something like Selenium, for which it would be good to follow some design pattern like Page Object. But this is something more specific and dependent on what we are testing and in this post, we want to focus on Cucumber itself.
Feature Files (Scenarios in Gherkin)
Creating a Feature
To begin we create a folder in the project where we will save the features that we are going to write in Gherkin. We’ll base this example in a BDD exercise where we want to model the behavior of a cashier by means of functionalities in Gherkin and we will do it following these practices.
Suppose we are interested in modeling the behavior of an ATM when we want to withdraw money:
- Inside the folder, we create a file with a .feature extension (for example “withdraw-money.feature”)
- We define a title that says what the functionality is. For example, “Feature: Withdrawal of money”
- We begin to write scenarios for our functionality
The description of a scenario is usually written as follows:
Scenario: As [concrete user]
I want [take a concrete action]
for [result or benefit]
The important thing is to explain briefly what you want to achieve with the scenario.
One way to start writing the feature can be this:
Feature: Money Withdrawal
Scenario: As an existing and enabled ATM user, I want to make a withdrawal to get money.
Some important points about feature files:
- The most advisable thing is to use one feature per system functionality, making sure the Feature is specific to a single functionality in particular and is as independent as possible from other functionalities.
- The best way to make our Feature files understandable to a client is to use the same language that they use to describe the functionality, therefore, it is always better to describe the actions as the client would.
Features and Scenarios
In Gherkin, scenarios are examples of individual behavior to establish acceptance criteria, so we may be interested in writing several by functionality to observe different results and make our test more complete (it’s recommended to write the positive scenarios first).
To describe the scenarios, Gherkin sentences are used: Given, When, Then, But and And.
The most important thing is that the steps briefly describe what you want to do in the functionality and not how you want to do it (this is the responsibility of the step definitions, explained below).
An example of a badly written scenario is this:
Given I authenticated myself with an enabled card
And The available balance in my account is positive
And the ATM has enough money
And the ATM has enough paper to print receipts
When I put the card in the ATM
And I input into the keyboard my card’s pin
And I press the confirm pin button
And I press the button next to the option to withdraw money
And I enter an amount less than or equal to my available balance
And I press the button to confirm the withdrawal
And I press the button to print the receipt
It’s better to avoid writing scenarios in this way because it makes them very long, with many unnecessary details, so they are harder to read and understand. Another disadvantage of writing them this way is that it makes them difficult to maintain.
Here’s a better and clearer way to write the scenario:
Scenario: As an existing and enabled ATM user, I want to make a withdrawal to get money.
Given I authenticated with a card enabled
And The available balance in my account is positive
When I select the option to withdraw money
And I enter the amount of money that is less than the amount I have available and the ATM’s available balance
Then I get the money
And The money I get is subtracted from the available balance of my account
And The system returns the card automatically
And The system displays the transaction completed message
Here are some important points about scenarios and steps in Gherkin:
- The statements must be written in order “Given-When-Then.” This is because ‘Given’ represents a precondition, ‘When’ an action and ‘Then’ a result or consequence of the action (user acceptance criteria). So writing a ‘When’ after ‘Then’, for example, would not be good conceptually and unclear.
- Neither should ‘Should-Given-Then’ be repeated per stage. To extend any of the sentences, ‘And’ is used. The reason for this is that a scenario represents an individual behavior, and if we define something of the style: ‘Given-When-Then-When…,’ we can surely divide it into more than one scenario.
- The sentences have to be consistent with each other and with the description of the scenario, that is, if the description of the scenario is written in the first person, the sentences should also be written in the first person.
- As much as possible, do not use many steps for a single scenario, the idea is that a user who does not know the functionality should be able to understand it by reading the scenario. The less you have to read to understand it, the better.
- Write the sentences to be explanatory and brief.
- Write the scenarios as we would like them to be presented to us.
- The ‘But’ statement works the same as ‘Then,’ but it is used when we want to verify that no concrete result is observed, for example:
Given I meet a precondition
When I execute an action
Then I observe this result
But I should not be able to see this other result
- It’s very important that the scenarios are as independent as possible, that is to say: scenarios can’t be coupled. For example, it’s not convenient if, in a scenario, we insert records in a database, the result of following scenarios depends on the existence of those records. Having coupled scenarios can generate errors, for example, if we have to run them in parallel, or if one fails.
How to Separate the Files?
When separating the features, the amount of files can be enormous, so then you have to think about how to make the division of features in different files.
A popular option is to have a file with the features that group everything related to one aspect of the application and even organize them in directories.
In a specific case, for an entertainment system, you might have this: In the first level we could have a folder, “Shows”. Inside, you have different features like creating, editing, deleting and everything that has to do with them. This way it is better organized and easier to locate everything and each test.
Scenarios with Concrete Data
BDD is somewhat similar to SBT (Sample Based Testing), in that it seeks to reduce ambiguities by showing examples. Considering this, perhaps the previous example would be better if we lower it to specific data, as in the following case:
Scenario: As an existing and enabled ATM user, I want to make an extraction to get money.
Given I authenticated with a card enabled
And The available balance in my account is $10,000
And The cashier has $100,000 in cash
When I select the option to extract money
And I indicate that I want to extract $1,000
Then I get $1,000 in the form of two $500 bills
And The balance of my account becomes $9,000
And the cashier keeps $99,000 in cash
And The system returns the card automatically
And The system displays the completed transaction message
In the first or third person?
A very common question that arises at the time of writing a scenario is the point of view that should be used. The usual question is: Should I write the scenarios in first or third person? The issue is more complex than it seems.
The examples used in the official documentation of Cucumber use both points of view, so it is not an exact reference to solve the problem.
Here are the arguments in favor of each:
The First Person
Dan North (considered the creator of BDD), as we found in a reference in Stack Overflow, recommends the use of the first person, and in fact it’s what he uses to write his scenarios in his article, “Introducing BDD.”
The use of the first person allows writing the scenario to be coherent with its description, which, as mentioned above, usually follows the form “As [concrete user] I want [to perform concrete action] for [result or benefit]”.
Given that the specific role or user for which the scenario is constructed is specified in the description, and the idea is to put oneself in the shoes of that user, the use of the first person can be a coherent form of writing.
The Third Person
The defenders of this position argue that the use of the first person makes the scenario reader lose reference to the role or the user that is being talked about. If I write in a step “I delete an article from the system,” who is the one that is doing it? An administrator, a particular user? A set of roles?
In some way, the use of the third person diminishes the risk or the difficulty of the reader making erroneous assumptions about who is the stakeholder(s) involved.
It’s also argued that the use of the third person presents the information in a more formal and objective way.
Conclusion
There is no general rule about the point of view to use to write the scenarios.
The important thing at this point, as already mentioned, is to maintain the consistency between the description of the scenario and its steps (not to alternate points of view), to respect the criteria used in the case that we are adding scenarios to an existing project and to favor clarity of what is written.
Other Key Words to Describe the Scenarios
Background
If in all the scenarios of the same feature, some preconditions are met, it is much more practical to use a Background than to write the same thing several times. This serves as a series of steps that will be executed before all the scenarios of the feature. Let’s see an example:
Feature: Money Withdrawal
Background:
Given The credit card is enabled
And The available balance in my account is positive
And the ATM has enough money
Scenario: …
It is recommended that the Background be as short as possible in terms of the number of steps, because if it is very long, it can be difficult to understand the scenarios that follow. It’s always better to have scenarios be as self-contained as possible, and in case you have a Background, make it as short as possible.
Scenario Outline
Scenario Outline is a type of scenario where input data is specified. They are very practical because, thanks to this, it’s not necessary to write a scenario by input data.
For example:
Scenario outline: Withdraw money with different card keys.
Given The credit card is enabled
And The available balance in my account is positive
And the ATM has enough money
When I put the card in the ATMAnd Enter the <pin> of the card
…
Examples:
| pin |
| 1234 |
| 9876 |
Doc Strings
Doc Strings are useful to add strings of long characters to a step in a neater way.
To use them, you must add the desired text in the step between three quote marks (“””). For example:
Scenario outline: …
Given …
When …
Then I get money
And the Confirmation message is displayed with the text:
“””
Dear Customer:
The following amount has been withdrawn from your account # <account>: <amount>.
Thank you for using our services.
“””Examples:
| pin | account | amount |
| 1234 | 112235489 | 5000 |
| 9876 | 668972214 | 6000 |
As you can see in the previous example, a Doc String (which is in itself an input data) can be used in combination with other input data to show data specific to the scenario that is being executed.
Data Tables
Data Tables, in their structure and usefulness, are very similar to Scenario Outlines. Their two main differences are:
- Data Tables are defined at the step level and not at the scenario level, so they serve to pass input data to a single step within the scenario.
- It’s not necessary to define a head, although it is useful and advisable to be able to reference the data more easily.
Example of the use of Data Tables:
Scenario: Withdraw money with different card keys.
Given The credit card is enabled
And The available balance in my account is positive
And the ATM has enough money
When I put the card in the cashier
And I enter the following <pin> and get the result <result>:| pin | result |
| 1234 | Error |
| 9876 | OK |
In the previous example, we added a second column “result”, to indicate the expected result according to the entered PIN (“1234” is incorrect and “9876” is correct). It is not necessary to use the Data Table in that way, but it is included as an example of how the input data can be used in a scenario.
Languages
Cucumber offers the possibility of writing the scenarios in different human languages, following the same conventions that we normally use in English.
To make use of this feature, the functionality must be headed with “# language:”, followed by the dialect code to be used (for example, “# language: es”, for Spanish).
In the official Cucumber documentation, you can find all the necessary information to use this feature, including the code of each dialect and the words that should be used for each language to replace the typical ones.
Tags
On certain occasions, it may happen that we don’t want to execute all the scenarios of our test, but rather group certain scenarios and execute them separately. Cucumber provides a way to configure this by means of tags. The tags are annotations that serve to group and organize scenarios and even features, these are written with the @ symbol followed by a significant text, examples:
@gui
Feature: …
@SmokeTest @wip
Scenario: …
@RegressionTest
Scenario: …
It is important to note that the tags that we specify to the titles of the Feature files will be inherited by the scenarios of the same, including Scenario Outlines.
If we have a Scenario outline under a tag, all the data examples that the scenario has will be executed under that tag.
Having assigned our tags, there are many ways to configure them in the execution in the tag section of @CucumberOptions. Some examples:
tags = {“@SmokeTest”} Execute all scenarios under the @SmokeTest tag
tags = {“@gui”} Execute all the scenarios under the @gui tag, as in the example we have a feature under this tag, all the scenarios of that feature will be executed.
tags = {“@SmokeTest, @wip”} Execute all scenarios that are under the @SmokeTest tag or under the @wip tag (OR condition).
tags = {“@SmokeTest”, “@RegressionTest”} Execute all scenarios that are under the @SmokeTest and @RegressionTest tags (AND condition).
tags = {“~@SmokeTest”} ignores all scenarios under the @SmokeTest tag
tags = {“@RegressionTest, ~@SmokeTest”} executes all scenarios under the @RegressionTest tag, but ignores all scenarios under the @SmokeTest tag
tags = {“@gui”, “~@SmokeTest”, “~@RegressionTest”} ignores all the scenarios under the tag @SmokeTest and @RegressionTest but executes all those under the tag “@gui”, if we follow the example it’s like running all the scenarios of the feature that are not under any other tag.
In short, tags are not only useful for organizing and grouping our scenarios/features (which contributes a lot to the clarity of the test), but also allow us to execute them selectively, such as, for example, executing the fastest scenarios more frequently.
Step Definition (Implementation of the Steps)
What we did previously was the specification of the steps of our scenarios, we describe what processes our test will follow, but we do not define how we want it to be done. This becomes the responsibility of the implementation of the Gherkin sentences that we write in the scenarios (step definitions).
The step definitions serve Cucumber as a translation of the steps we write in actions to execute to interact with the system.
Although the examples that will be given below for the implementation of the steps are developed in Java, it should be mentioned that Cucumber can also be used with JavaScript, Ruby, C ++ and other languages.
To start writing step definitions, if we are working on an IDE with dependencies of Gherkin and Cucumber already installed, it will suggest us to implement them (they will appear underlined), and it will allow us to create a .java file or choose one where we already have steps implemented. Choosing any of these two options will generate a method in the class, for example if we decide to create a step definition for the step:
Given The credit card is enabled
We will automatically generate a method with an annotation, where the header text will match the description of the step:
@Given(“^The credit card is enabled$”)
public void verifyEnabledCard() throws Throwable {
// Write code here that turns the phrase above into concrete actions
throw new PendingException();
}
In the case that the step includes input data defined through Scenario Outline or Data Tables, these data are included in the annotation as regular expressions, and in the method as received parameters:
@When(“^Enter the \”([0-9]+)\” of the card $”)
public void enterPIN(int pin) throws Throwable {
// Write code here that turns the phrase above into concrete actions
throw new PendingException();
}
Automatically when we do this, the step in the feature (the sentence in Gherkin) already recognizes where the implementation is. Here are some important points when implementing step definitions:
The most advisable thing is to create step definitions that only have to be implemented once and reused in many scenarios (even of different features).
This is practical not only to save the amount of code that has to be written, it also contributes a lot to the maintainability of the tests since it will eventually be less the number of step definitions that we will have to modify in any case.
One way to reuse step definitions is to define them in Scenario outlines and parameterize them.
Further Resources
We leave you some references in case you want to continue reading about BDD, good Cucumber practices, or Gherkin:
- https://automationpanda.com/2017/01/25/bdd-101-introducing-bdd/
- https://hiptest.com/docs/writing-scenarios-with-gherkin-syntax/
- https://docs.cucumber.io/gherkin/reference/
- https://www.foreach.be/blog/9-tips-improving-cucumber-test-readability
- https://saucelabs.com/blog/write-great-cucumber-tests
- https://blog.codeship.com/cucumber-best-practices/
- https://automationpanda.com/2018/02/03/are-gherkin-scenarios-with-multiple-when-then-pairs-okay/
- https://automationpanda.com/2018/01/31/good-gherkin-scenario-titles/
- https://automationpanda.com/2017/01/30/bdd-101-writing-good-gherkin/
- http://toolsqa.com/cucumber/background-in-cucumber
- https://www.engineyard.com/blog/15-expert-tips-for-using-cucumber
- http://toolsqa.com/cucumber/cucumber-tags/
- https://stackoverflow.com/questions/34839651/what-person-and-mood-should-i-use-in-gherkin-specflow-given-when-then-statements.
- https://www.spritecloud.com/2018/03/the-3-most-common-mistakes-writing-gherkin-features/
- https://automationpanda.com/2017/01/18/should-gherkin-steps-use-first-person-or-third-person
Recommended for You
Webinar Summary: BDD and CD with Lisa Crispin
When to Automate a Test?


