Learn all about automated functional testing. This guide highlights challenges, strategies, and essential tools, emphasizing the synergy between functional and automated testing. Step in and enhance your processes and results.

By Federico Toledo and Matías Fornara
In this guide, we’ll delve deep into the who, what, where, when, why, and how of functional test automation. You’ll uncover both the IT and business benefits of test automation and gain insights into the right moments to opt for automation. Plus, we’ll impart some top-tier practices and strategies to foster your efforts to yield optimal results.
By the time you finish reading, you’ll be poised to present a robust plan for functional test automation to your team and kickstart its execution.
Explore our test automation case studies to see how we have helped clients like Singularity University, Threads and PedidosYa streamline their testing processes with automation.
What is Automated Functional Testing?

If you take the traditional definition of automation from industrial automation, you can say it refers to a technology that can automate manual processes, bringing about several other advantages:
- Improvement in quality, as there are fewer human errors.
- Improvement in production performance, given that more work can be achieved with the same amount of people, at a higher speed and larger scale.
- Improvement in production performance, given that you can achieve more work with the same amount of people, at a higher speed and larger scale.
This definition also applies perfectly to automated functional testing (or checking).
Why Automating Functional Testing?
Functional testing primarily focuses on the software’s behavior according to its requirements, while automated testing emphasizes the methodologies, tools, and scripts used to execute these tests automatically.
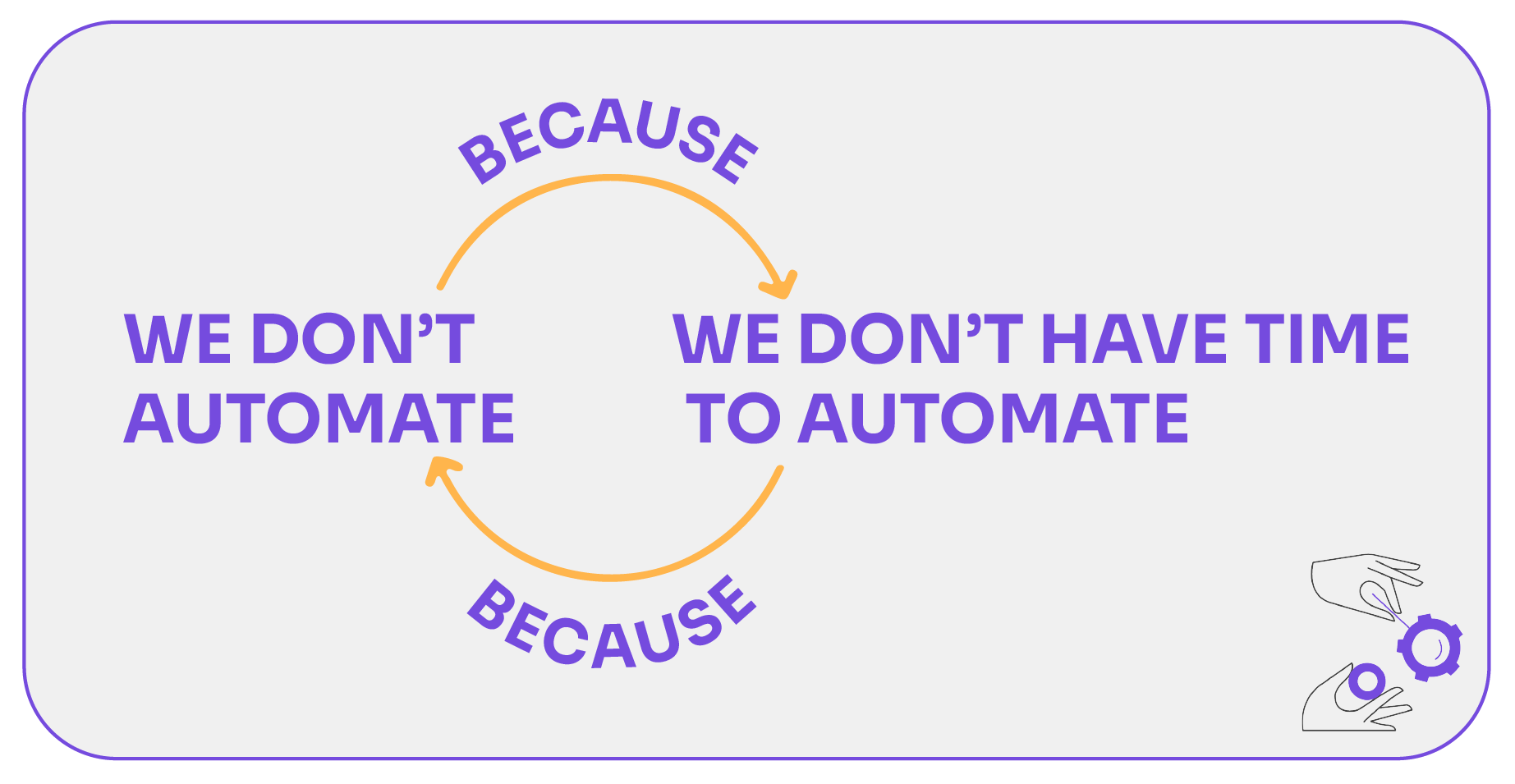
Now, we would like to bring the “Zero Accumulation” theory forward.
Basically, the features keep growing as time goes on (from one version to the next) but the tests do not grow. In fact, we haven’t heard of any company that hires more testers as it develops more functionalities.
As a product grows, you have to choose what to test and what not to test, leaving many things untested.
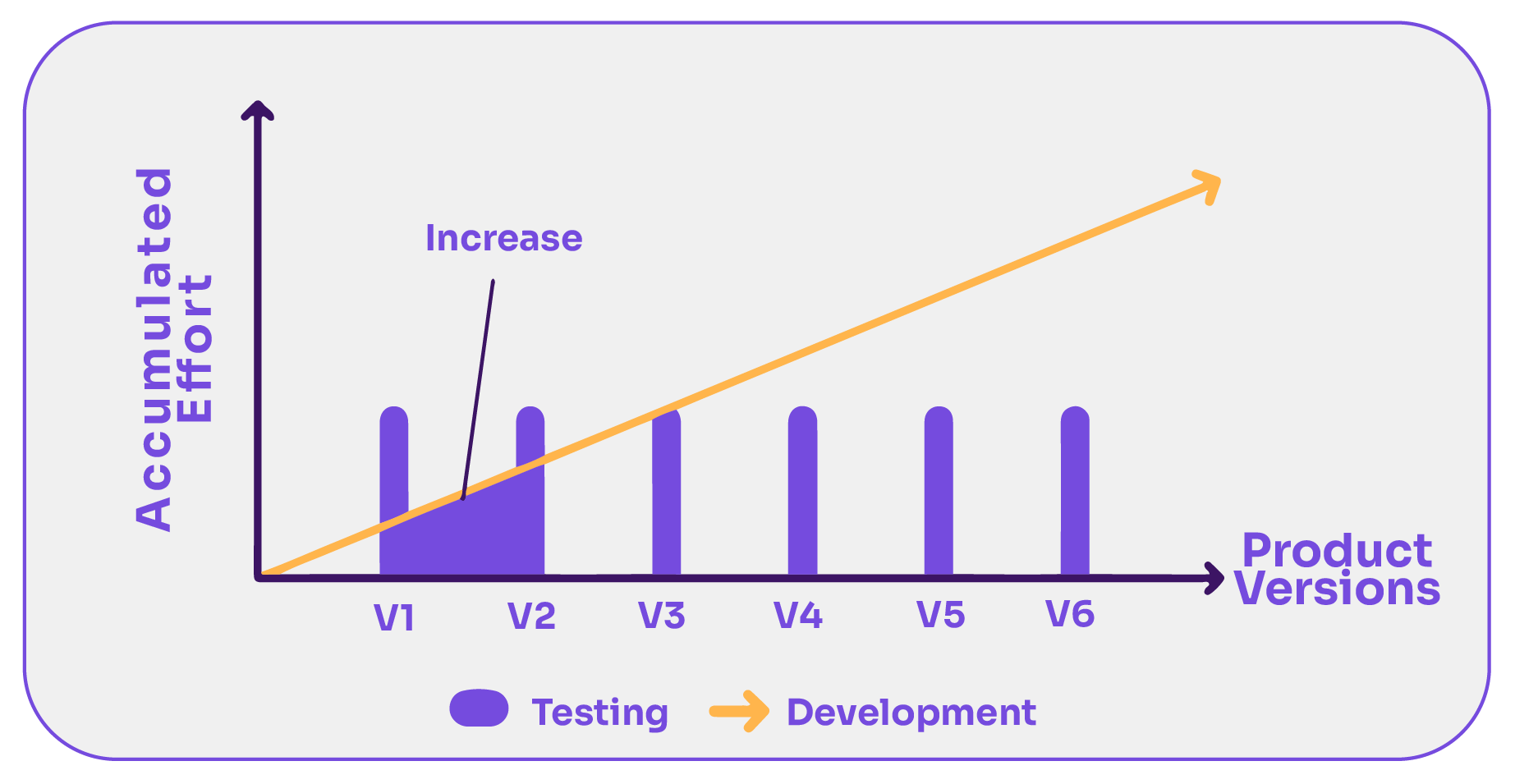
Test executions are not cumulative. Every time a new version of the system is released, it’s necessary (well it’s desirable, yet should be necessary) to test all the accumulated functionalities. Not just the ones from the last addition. This is because some of the functionalities implemented in previous versions may change their desired behavior due to the new changes.
The good news is that automation is cumulative. It’s the only way to make testing constant. The challenge is to perform testing efficiently, in a way that pays off.
When people say they’re doing automated functional testing, they are using an automated functional testing tool to automatically check that the software functions as expected. It’s a blend of both worlds – enhancing functionality while saving time and effort.
Teams leverage test automation tools to optimize the functional testing process, for both mobile and web applications. By incorporating continuous testing into the mix, there’s a seamless flow in test management. This approach enhances test coverage, boosting all functional tests to be thorough and reflective of user needs, resulting in more reliable software products.
Moreover, as performance testing increasingly intersects with functional testing in agile environments, ensuring both functional correctness and performance efficiency becomes essential.
Building on these tools and processes in the software realm, automation testing has become paramount. It helps validate that applications function correctly across all browsers and platforms, thanks to cross-browser testing. All this in line with the defined specifications.
With a broad array of automation tools and testing tools available in the market, you can now choose tools that best fit your business requirements and optimize your testing process.
These tools not only promote accuracy but also expedite the testing cycle, allowing for swifter and more efficient software delivery. In this light, automated functional test firmly cements its place as a cornerstone in the evolving landscape of software testing.
Want to learn more about why you should automate functional testing? Don’t miss this article.
What is the Difference Between Functional Testing and Automated Testing?
First and foremost, we need to know these crucial differences. While functional testing (also called manual testing) and automated testing serve different purposes in the software development cycle, they both aim to ensure the production of high-quality software.
As automation becomes increasingly prevalent, it’s crucial to distinguish between these two testing approaches. Dive into this article to learn more about functional testing vs. automated testing.
Which Types of Tests Can Be Automated?
As we are focusing on automated functional testing in this guide, we have to discuss regression tests.
Regression Testing
Regression tests are a subset of scheduled tests chosen to be executed periodically, for instance, before a product release. They aim to verify that the product hasn’t suffered any regressions.
Regression testing is the process of testing software applications to ensure that recent changes in code, such as new features or bug fixes, have not adversely affected existing features. Its primary goal is to catch unintended side effects that might arise after modifying the software.
You can perform regression testing manually or by using automated tools. It is an essential part of the software development lifecycle for maintaining software quality. Whenever a change is made to the software, you should run regression tests to verify if the rest of the system remains intact and functions as expected.
Although it’s one of the most popular types of tests to automate, it’s not the only use for test automation. Take a look at this article to know all the types of tests that can be automated!
Regression Testing in Agile
Regression testing in Agile helps you check if recent code changes haven’t adversely affected existing functionalities. As teams continuously add or modify features in Agile sprints, it’s necessary to run regression tests to catch any unintended side effects. This practice plays a crucial role in validating that software remains robust throughout its iterative development.
Automated testing tools are essential for efficiently managing and executing these tests due to the recurring nature of Agile cycles.
How to choose a quality partner for test automation that fits your specific needs? Click here to uncover the essential insights.
Benefits of Automated Functional Testing

Embarking on the journey of automated functional testing offers more than just bug detection. While many consider the discovery of errors as the prime metric, the advantages begin unfolding from the very initiation of test modeling and specification. Plus, it’s key to remember that the insights derived from test results are equally invaluable.
- Immediate Benefits from Test Modeling: Contrary to the belief that the primary benefit comes only from identifying an error, the rewards actually emerge the moment you initiate the process of formalizing the tests.
- Verification Beyond Error Detection: Discovering an error isn’t the sole merit. Verifying that the tests are scrutinizing the right parameters and ensuring they function as they should is equally vital. As highlighted by an article in Methods and Tools, automation often uncovers a significant number of bugs.
- Rigorous Testing During Automation: The process of automation requires diving deep into functionalities, experimenting with varied data, and more. Often, this means that while you’re trying to automate, you’re also inadvertently executing rigorous testing.
- Beware the Pesticide Paradox: If you’ve automated tests for one module and believe that’s sufficient, do you halt further testing? This presents a risk: the automated tests might not encompass all functionalities, mirroring the pesticide paradox.
- Quality Over Quantity: It’s a misconception that a vast number of tests equate to comprehensive testing. You might have thousands of tests, but if they aren’t thorough, if they’re too similar, or if they bypass critical functionalities, they’re not as effective as you think.
- True Value of Automation: It’s not about the sheer number of tests or their frequency, but about the actionable insights they yield.
Learn more about the benefits of automated functional testing and when it is a good time to automate.
What Percentage of Functional Tests Should be Automated?
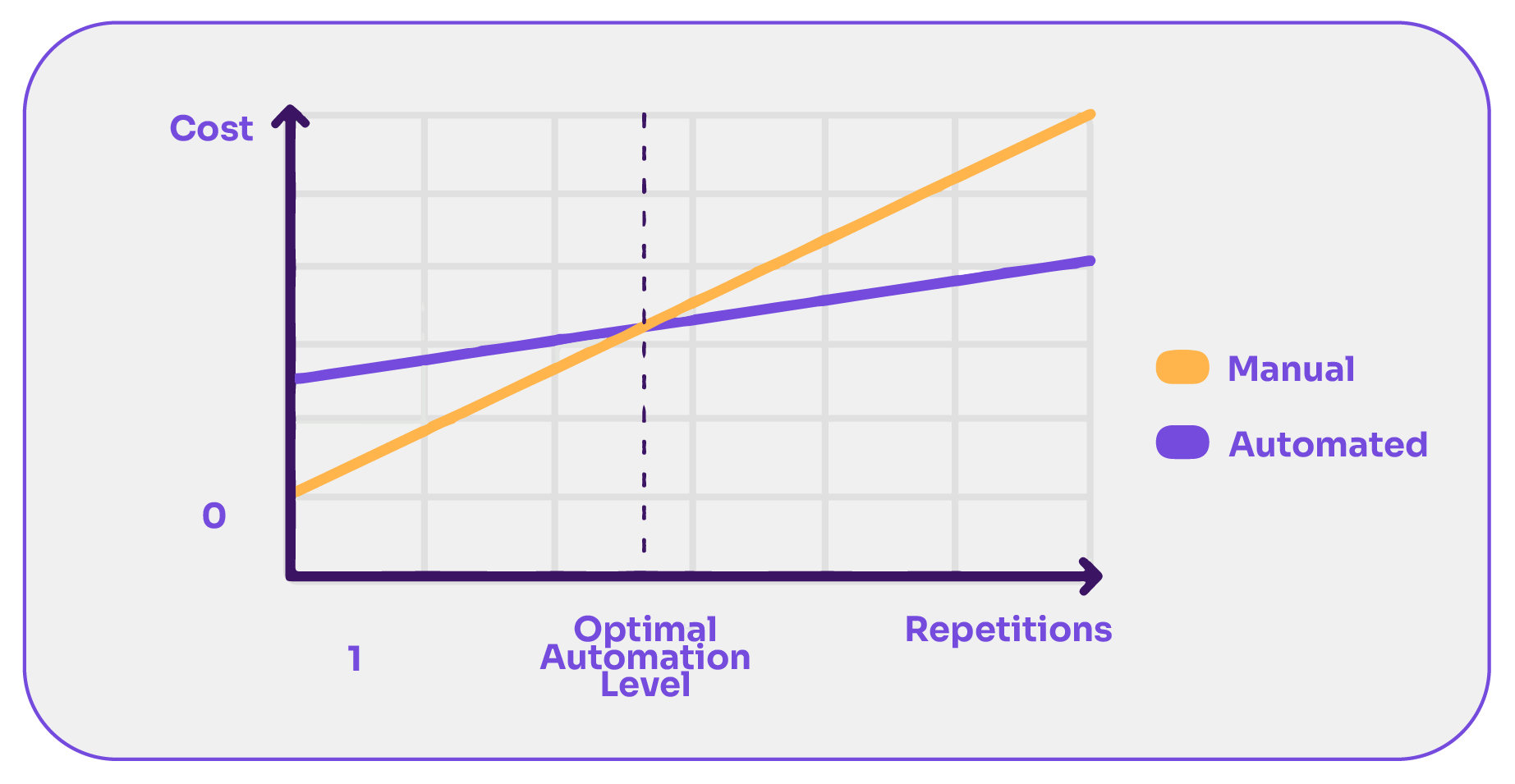
From our experience, it’s safe to say that there is a high ROI in test automation. We’ve seen that the cost of a single defect in most organizations can offset the price of one or more tool licenses. Also, coding defects found post-release can cost up to 5x more to fix than those found during unit testing.
While there isn’t a one-size-fits-all percentage for how much functional testing you should automate, the decision depends on the ROI and the repetitiveness of tests.
Automation offers substantial benefits, including the high ROI where the cost of post-release defects can outweigh tool licensing costs. It brings value in improving software quality, reducing operational issues, and decreasing bug-fixing costs. Modern tools, like Testim.io and mabl, enable even non-coders to automate tests efficiently.
However, the key is to automate frequently executed tests and weigh the cost of automation against the anticipated number of test executions. If you need to run the same test case multiple times across various versions and platforms, it’s often more cost-effective to automate.
Note that the cost of a single repetition is greater in the automated case. Next, we share a graph that represents this hypothetically. Where the lines cross is the inflection point at which one makes more sense cost-wise than the other.
If you need to execute the test case less than that number of times, it’s better not to automate. Conversely, if you are going to test more than that number, then it’s better to automate.
Read more about what percentage of functional tests should be automated and go into an in-depth breakdown of the math behind the potential ROI of test automation.
Types of Automated Functional Tests
Automated functional tests can be a game-changer in agile environments, enabling a faster and more efficient development process.
The Agile Test Automation Pyramid, introduced by Mike Cohn, emphasizes the importance of a strong foundation with unit testing. These tests individual ‘units’ of software like functions or methods.
There are various methods to automate unit testing:
- The Test-First approach linked with Test-Driven Development (TDD)
- The traditional Test-Last method
- Boundary Testing for the extremes
- Mocking and Stubbing for simulating dependencies
Beyond unit tests, API testing facilitates smooth communication between software systems. So there’s a need to choose between code-based solutions or GUI tools like Postman for this. Lastly, UI testing focuses on the interface’s functionality.
To go deeper, check our guide on end-to-end API testing.
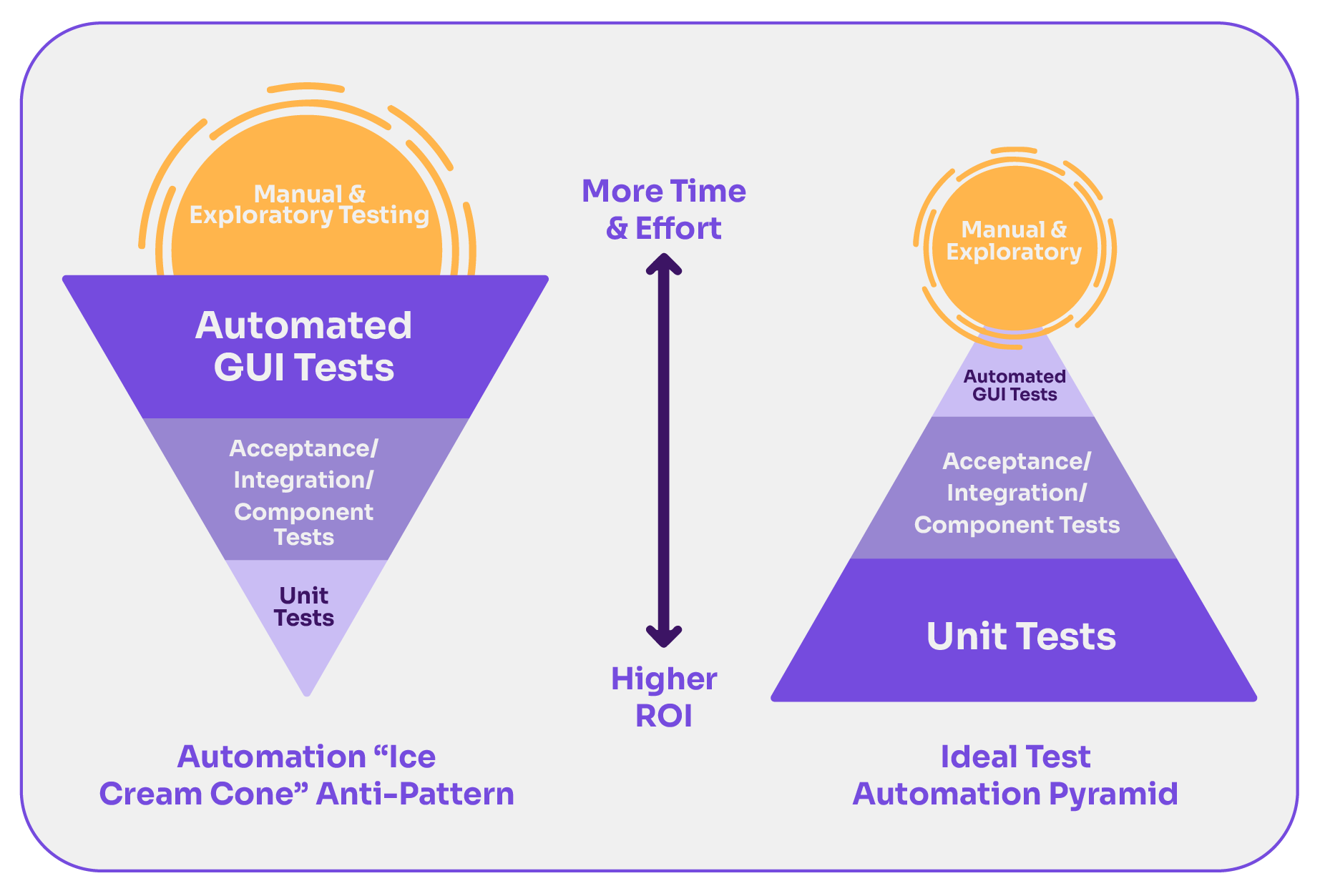
When automation focuses predominantly on the UI level, it’s about bug detection. However, the agile pyramid promotes bug prevention. This methodology is more beneficial as it grounds a strong unit testing base and expands to integration and UI phases.
You can achieve UI automation through Record and Playback. This is gaining traction thanks to new tools with enhanced features, or through the more traditional Scripted Testing, where tests are coded.
Record and Playback is a beginner-friendly approach. Just like recording a video, you perform a series of actions on the application, and the tool records them. Later, you can ‘playback’ these actions to see if the UI behaves as expected.
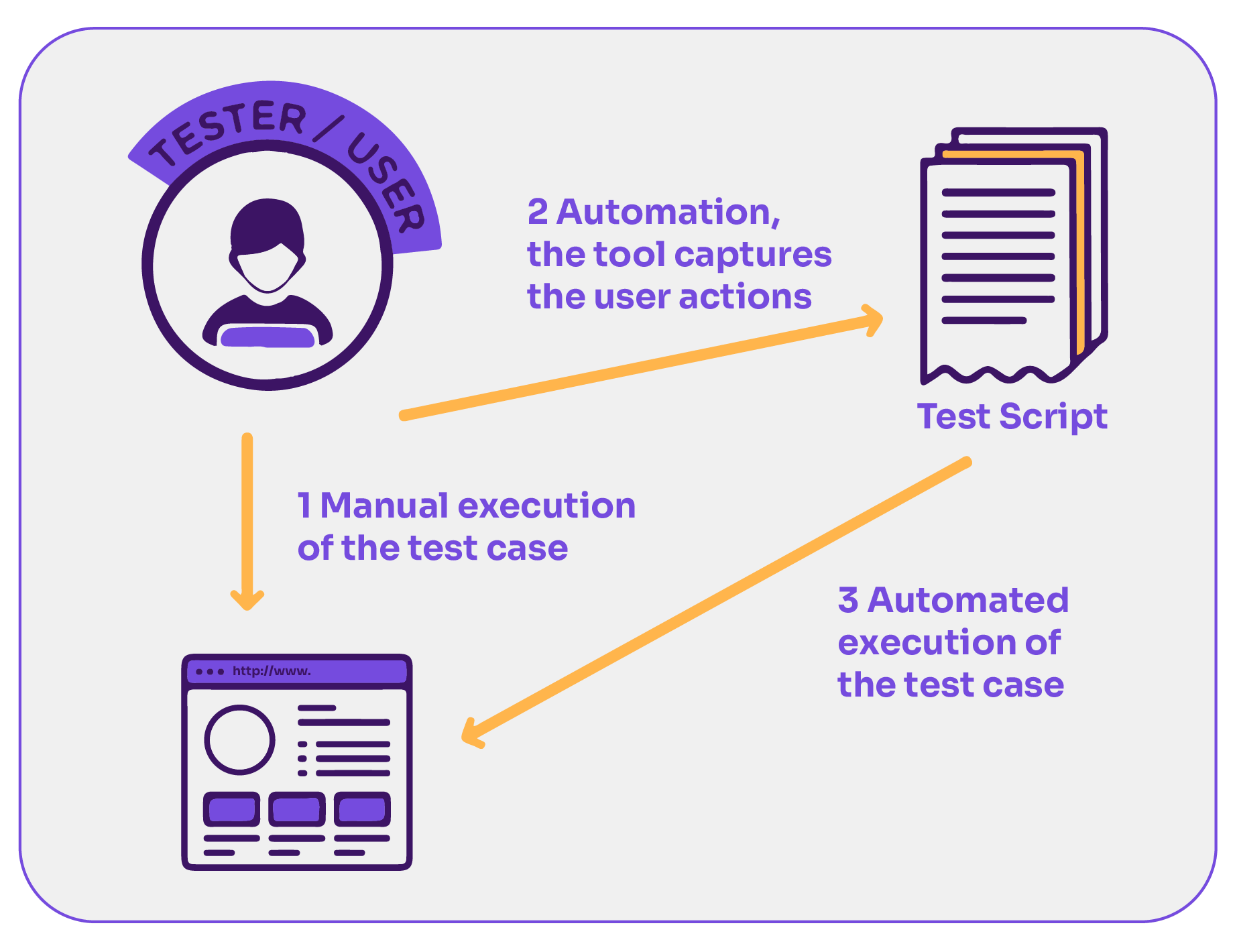
Another advanced technique is Model-Based Testing, which utilizes models for test design, either tailor-made for testing or derived from development processes. This approach allows for working at a higher degree of abstraction, without having to deal with technical difficulties. All this focusing only on the model of the problem, making the tests easier to understand and maintain.
For those aiming to enhance their testing process and outcomes, it is indispensable to gain a deep understanding of these automated testing methods.
In this post, we’ll continue discussing mainly automation with scripting, relying on tools like Record and Playback. These tools allow teams to parametrize their actions and follow a Data-driven Testing approach.
In addition, we’ll make suggestions related to test design. We’ll cover different aspects of the automation environment, considering the design will be done manually, not necessarily with model-based technique tools.
Overcoming Common Challenges of Automated Functional Testing

Automating functional tests offers a range of benefits, but it also brings forth challenges. The key is to find efficient ways to navigate these challenges. In this section, you’ll discover actionable strategies for mastering automated functional testing.
Test Maintenance
As a product evolves, maintaining automated tests becomes paramount. Especially when dealing with a growing number of tests, an organized and clear structure can make this task much easier and less chaotic.
Denomination
Choosing the right naming convention for your test cases and organizing structures is a small step that can yield big results. Aim for informative yet concise names that resonate with your team and adhere to style guidelines.
Also, consider a folder structure that segregates general test cases from specific modules, making it simpler to reuse and integrate tests elsewhere. Occasionally, you might also need temporary test cases, which can be uniformly prefixed for easy identification.
Comments and Descriptions
It’s beneficial to attach a brief description to each test case, laying out its objective. Furthermore, annotating test steps and data goals can streamline the test execution and review process.
“Read Me” File
Imagine handing over a complex device without a user manual. That’s what skipping a “Read Me” file in your test framework is like. Equip your team and potential users with a comprehensive guide detailing the purpose, technologies, dependencies, instructions, and collaboration process related to your test framework.
Test Cases and Test Scripts
The eternal debate: One script per test case or a single script for multiple test cases? Both approaches have merits. A modular approach, which involves breaking down a test case into smaller, reusable modules managed by a singular script, often proves to be the most efficient. This allows for greater flexibility, maintainability, and clarity.
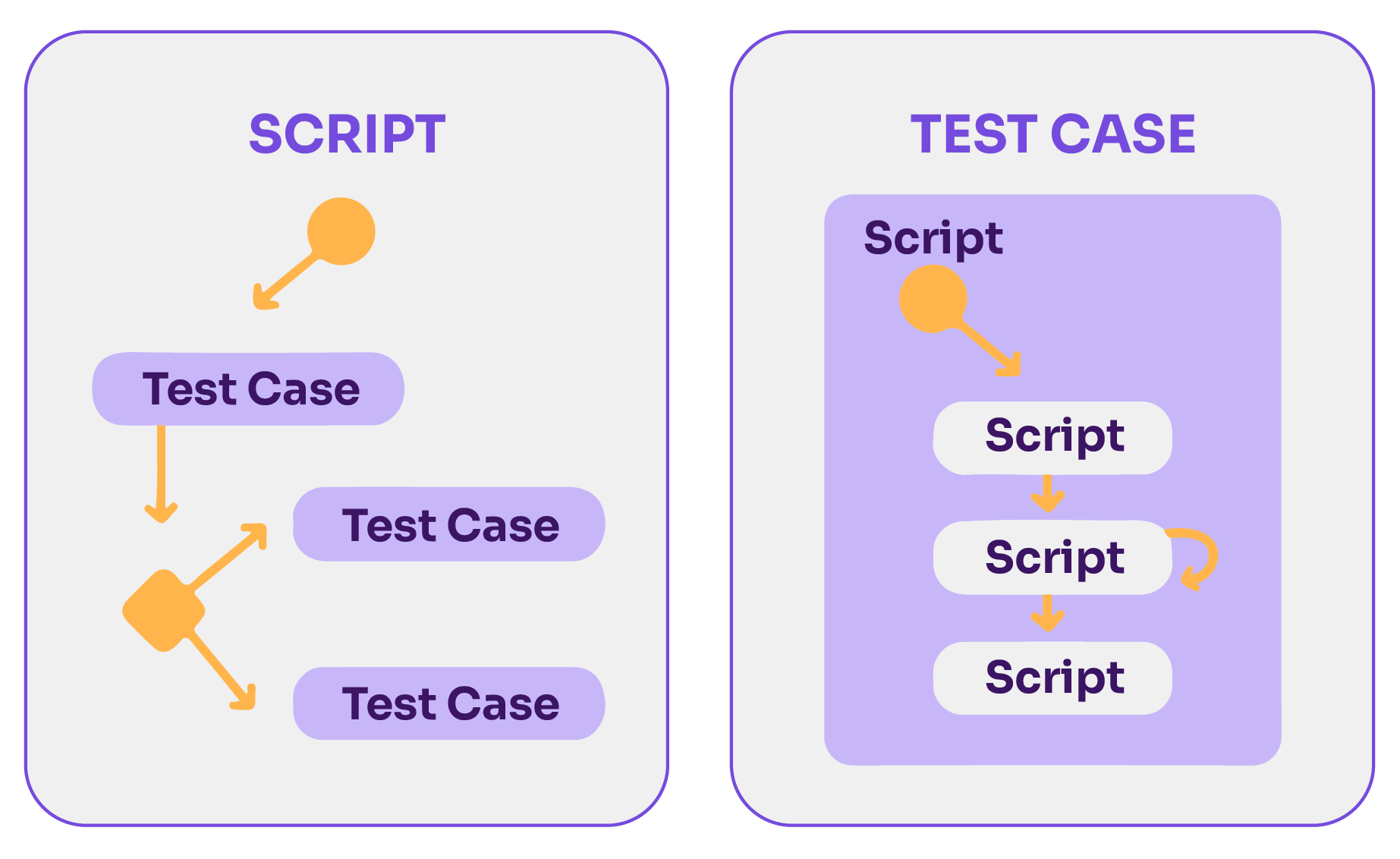
The modular approach to scripting comes with a plethora of benefits:
- Maintenance: It simplifies updates and changes.
- Reusability: You can reuse modules across different scenarios.
- Flexibility: It’s possible to make adjustments at various stages without affecting the entire script.
- Clarity: A structured approach allows for a clearer understanding of the test flow and objectives.
To further amplify the efficiency, maintaining a matrix linking test cases with related scripts can help track the impacts of requirement changes on tests and scripts.
Avoiding False Positives and False Negatives
False results in automation can be a nightmare. Testing, in essence, should provide accurate results. So, how do we avoid these pitfalls in automated testing? The answer lies in meticulous test design, regular reviews, and understanding the root causes of false results.
We’ve explained in detail in this post how to avoid false positives and negatives in your test automation.
Testing Third-Party Services
Interactions with third-party services or applications may add another layer of complexity. Whether you’re dealing with intricate logic, web service integrations, or the proverbial rocket launch, remember that your automation tool’s primary goal is to emulate user interactions. This means, in many cases, the underlying complexities aren’t as concerning as ensuring the user interface behaves as expected.
For tasks outside the graphical user interface—like database queries or file transfers—most tools offer specific functionalities or allow custom programming. However, simulating or truly connecting to external services might be tricky. Mock Services, such as SoapU or Postman, can replicate external services and facilitate efficient testing.
How to Perform Automated Functional Testing

Let’s say you already have your test cases designed. You’ll start by checking the functionality inventory (or backlog or wherever you store this information) and assign a level of priority to each. Afterward, you should assign priority to each test case prepared for each of the different functionalities.
This organizing and prioritizing will help divide the work (in case it’s a group of testers) and put it in order, given that grouping the test devices by some criteria. For instance, functionality is highly recommended.
You would be better off defining test case designs for automated testing at two levels of abstraction.
On the one side, you have what we will call abstract or parametric test cases. On the other hand, there are the so-called specific test cases, also known as concrete test cases.
Let’s review these concepts and apply them to this particular context.
Abstract test cases are test scripts that, when indicating what data will be used, do not refer to concrete values. Instead, they relate to equivalency classes, or a valid set of values, such as “number between 0 and 18”, “string of length 5” or “valid client ID”.
On the other hand, there are concrete test cases, where abstract test cases have specific values. For instance, they use the number “17” or the “abcde” string, and “1.234.567-8,” which could be considered is a valid identifier. These last ones are the ones you can actually execute and that’s why they’re also called “executable test cases”.
It is important to distinguish between these two “levels” as you will work with them at different stages of the automation process. This is to follow a data-driven testing approach, which greatly differs from simple scripting.
For automated test scripts, data-driven testing involves testing the application by pulling information from external data sources, like databases or spreadsheets. Rather than directly coding data into test scripts, this method enhances flexibility. It allows you to add diversity to your tests merely by extending your data set.
In other words, you parametrize the test case, allowing it to run with different data. The main goal is to be able to add more test cases by simply adding more lines to the test data file.
In addition, the concept of a testing oracle helps distinguish between valid and invalid outcomes. When building your test suite, consider grouping test cases either by their functionality or their level of importance. And a word to the wise: if one function causes a test suite to stumble, diving into dependent tests might not be the best use of time.
Test Suite Design
Tools typically let you group test cases to organize them and run them all together. You can define the organization by different criteria such as module or functionality and criticality. You could even combine these approaches by using crossed or nested criteria.
Defining dependencies between suites can be highly interesting, given that there are some functionalities that if they fail, directly invalidate other tests. It makes no sense to waste time by running tests that you know will fail.
Meaning, why run them if they don’t bring any new information to the table? It’s better to stop everything when a problem arises attack it head-on and then run the test again until everything is working properly (this follows the Jidoka methodology).
Test Automation Plan

In the digital age, testing isn’t just an afterthought—it’s an integral part of the software development process. You should think this task out well and plan it from the beginning, even before planning development.
If you’re diving into automation, planning is your best ally. From automation setup to maintenance and from bug detection to their fixes, every step needs meticulous planning.
Managing Test Environments
Managing your test environments is non-negotiable. Think of it like setting the stage for a play. You need:
- The application’s sources and executables.
- Test devices and their data.
- Updated database information specific to the testing environment.
- Appropriate images or docker files (if using Docker.)
Here’s a tip: You might have tests with different requirements. Instead of creating many environments, consider having database backups tailored to specific tests.
However, ensuring synchronization among these elements is key. After all, when a test flags an error, it should be because of a genuine issue, not an environmental mismatch.
When and Where to Run Automated Tests
How often should you run automated tests? While “frequently” sounds ideal, practicality often dictates otherwise. Remember:
- If tests are quick, run them all.
- If they take time, prioritize based on risk and recent application changes.
As for where to run these tests, you’ve got options:
- Development Environment: For developers, speed is essential. Fast feedback loops here help iron out issues quickly.
- Integration & Testing Environment: Here, more extensive regression tests ensure previously spotted issues remain resolved.
- Pre-production & Production Environment: Before handing off to the client, the application undergoes testing in an environment mirroring the actual production setup. Automated tests can be of great value here, enabling the final product to be as polished as possible.
Don’t forget: while UI tests are invaluable, they do take time. Hence, maximizing tests at the API level can save significant time during regression.
We invite you to learn how to enhance your API testing strategy through the most well-known heuristics and a new heuristic proposed by our team in this article.
Automated Functional Testing Tools
Venturing into the realm of automated functional testing tools, there are a plethora of options available, each designed to cater to different testing levels – be it Unit, API, or UI.
Popular Unit Testing Tools
- JUnit: Predominantly used for Java applications, JUnit is a simple framework to write repeatable tests.
- NUnit: This is for .NET applications. Similar to JUnit in its approach, but tailored for the .NET environment.
- TestNG: Evolved from JUnit, TestNG is designed for high-level parallel execution.
Popular API Testing Tools
- Postman: A popular choice for many, Postman makes API development faster and easier.
- Insomnia: A free, cross-platform desktop application that simplifies the interaction and design of HTTP-based APIs.
- SoapUI: Tailored for both SOAP and REST API testing, SoapUI is a comprehensive tool.
- Rest-Assured: For Java developers, Rest-Assured simplifies the process of testing and validating RESTful APIs.
Get to know our TOP 15 API automation tools in this article.
Popular UI Testing Tools
- Selenium: Probably one of the most well-known tools for automating web browsers. Whether you’re testing a straightforward web page or a complex web application, Selenium is an open-source tool, versatile and widely adopted.
- Appium: For mobile applications, Appium is a top pick as an open-source tool. It allows testing across both Android and iOS platforms, ensuring your mobile apps shine regardless of the device.
- Cypress: Designed for modern web applications, it provides real-time reloading and automatic waiting, making UI testing smoother and more intuitive.
- Mabl: A low-code, auto-healing, SaaS solution that aims to simplify test creation and maintenance and make them scalable as well as spend less time fixing tests.
- Protractor: Tailored for Angular applications, Protractor runs tests in a real browser, interacting with the app as a user would.
- Testim.io: Testim uses artificial intelligence to speed up the authoring, execution, and maintenance of automated tests.
- Reflect: Reflect offers scriptless, cloud-based end-to-end testing. You don’t need to write test scripts; instead, you perform actions on your site, and Reflect records and replays them.
- GhostInspector: This tool lets you build or record automated browser tests and then run them continuously from the cloud.
Partnering with us means gaining access to a wealth of expertise and top-tier testing tools. We’re not just service providers; we’re your partners in navigating the complex world of quality software. Our goal is to empower your teams, boost your quality, and accelerate your time to market.
Best Practices for Automated Functional Testing

Page Object Pattern
In our automation journey, we’ve come to realize one thing: maintainable code is gold. It’s the difference between constantly chasing updates and confidently knowing your tests will hold up. Design patterns, especially the Page Object Pattern, have been our guiding light.
Think of it this way: if a button changes in your app, would you rather rework 100 tests or just tweak one reference? That’s the magic of encapsulation.
The Page Object Pattern proposes having an adaptation layer conformed by specific objects to manage the interaction between the test cases and the application under test. To do so, you need to store the different element locators in a very organized way. If you want to see some good examples, check this.
Which problem are you solving by having maintainable code? If you have 100 test cases that interact with a certain button and the development changed its element locator, then you would need to maintain 100 test cases or at least 100 lines of code!
The solution for that is very simple: encapsulation. You have to have the element locator defined in one single place and reference the element from the 100 test cases. Then, if the change happens, you only need to maintain one line of code and all your test cases will work properly.
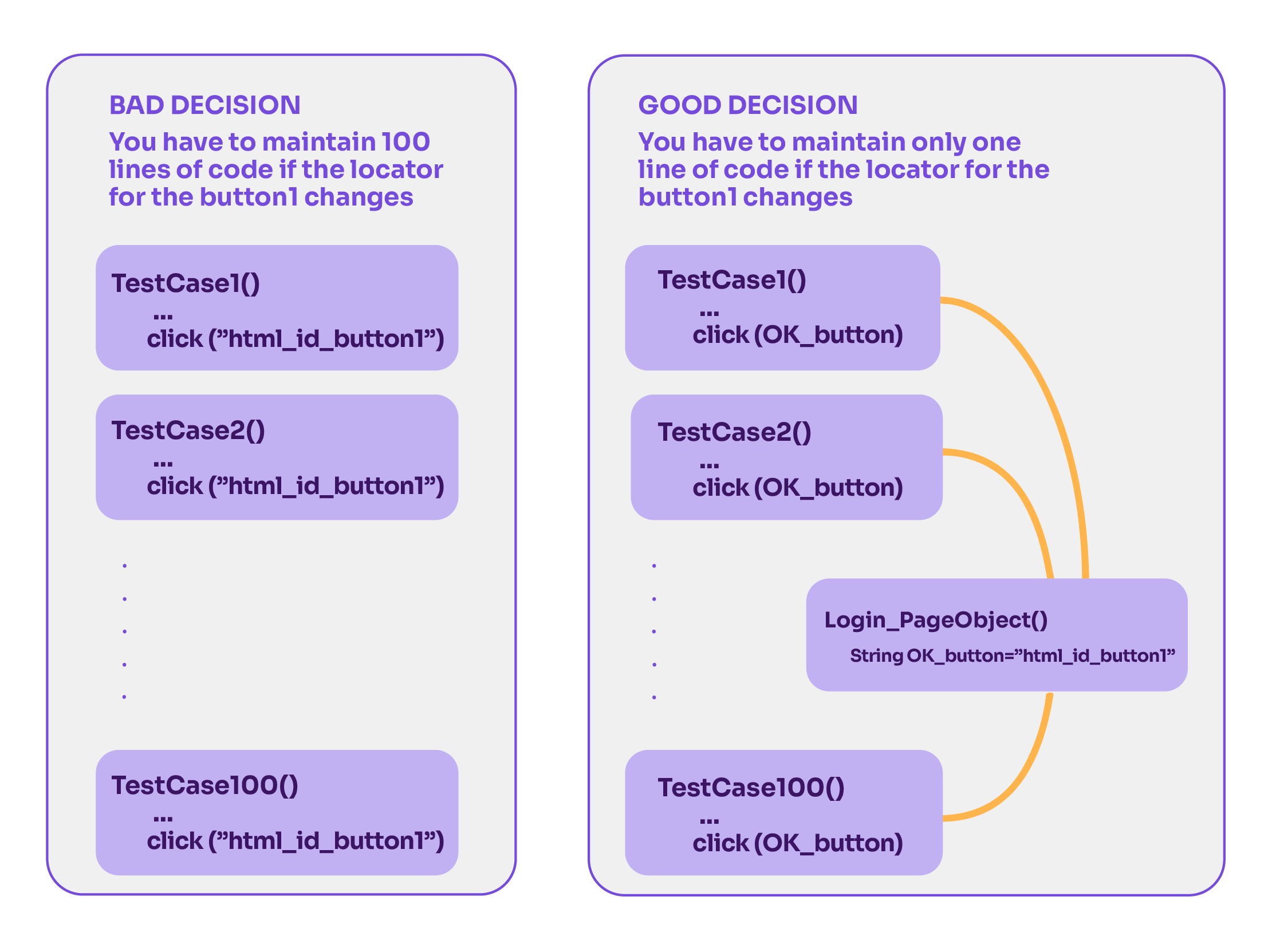
Going one step further, you can add even more encapsulation and abstraction to your test architecture. For instance, it’s possible to define different test methods in the page objects, including common actions.
While you can trust the Page Object Pattern as a reliable ally, other patterns like Screen Play await exploration. Additionally, you can use any other design patterns within the framework to improve the code’s maintainability.
Test Design According to Goals
Setting clear goals is fundamental. When it comes to test automation, having a roadmap is essential. You will have to make certain decisions about going one way or another, selecting certain test cases instead of others and designing them with a certain approach or strategy.
Do you seek consistent testing or aim to detect those elusive regression errors earlier? Pinpointing our goals upfront saves time and sidesteps potential pitfalls down the line.
Risk-Based Testing
With our goals set, how do we decide on priorities? This is where risk-based testing shines. It guides us toward truly crucial test cases. We consider factors like business significance, potential financial implications, and those binding SLAs. At times, the implications are significant, especially with sensitive data at stake. With risk-based testing, we’re not just testing; we’re making informed choices.
For more on risk-based testing, check out this post.
Now, Time to Automate!

After reading this, we hope you feel confident in getting started with your functional test automation efforts. We’d like to share one last thought….
“Automation does not do what testers used to do, unless one ignores most things a tester really does. Automated testing is useful for extending the reach of the tester’s work, not to replace it.” – James Bach
We highly agree. Automation can’t replace a tester’s job, but it can make it better and more encompassing.
You should not automate everything, and you ought not to attempt to completely replace manual testing. Some things cannot be automated, and sometimes it is easier to do something manually than to automate it.
In fact, if it were possible to run all testing manually, it might be much better, since that manual execution can reveal other issues at the same time. Do remember that automated tests check, but don’t test. The problem is that some things take more time to check manually. This approach doesn’t fit with our industry’s relentless drive to constantly deliver better releases and products.
In the dynamic realm of continuous delivery and integration, manual testing alone falls short. It lacks the efficiency, speed, and scalability required to keep pace with our ambitions for rapid development and frequent releases. That’s why automation is so critical.
We hope this guide helps you in your endeavor to automate functional tests. Please feel free to reach out and comment below sharing your experience with automated functional testing.
Looking for a Quality Partner for Test Automation? Abstracta is one of the most trusted companies in software quality engineering. Learn more about our solutions, and contact us to discuss how we can help you improve your test automation strategy.



How to Quickly Set Up Test Automation in CI/CD
Here’s a mechanism to shorten the setup time for automated tests using Selenium inside a Jenkins pipeline Something you often hear about Continuous Integration (CI) is that it helps identify problems earlier, but does it really? CI is a practice whereby a team of developers integrates…

Provar Automation: New Partnership Between Abstracta and Provar
We are delighted to tell you that we have strengthened ties with Provar. Through this strategic partnership, we are leveraging the Provar Automation tool and much more. It’s not a new partnership, but there’s a lot of news on the way and, before diving into…




{kind=link}